
作者:趙英傑
出版社:旗標科技股份有限公司
出版日期:2019.7.4
頁數:576頁
定價:NT$650
- 超圖解程式語法、人人都能看得懂
- 實用專案邊做邊學、擺脫枯燥語法
- 豐富多元應用、動手實作時數個專案
- YouTube影片自動下載、商品詢價網路爬蟲、Google試算表自動化、Flask網站建置、資料庫與留言板、LINE聊天機器人、圖檔浮水印產生器、自動縮圖產生器、人臉偵測器、人臉辨識、家電控制、刷臉門禁系統…
Python是Guido van Rossum(吉多‧范羅蘇姆)在90年代初期設計出的程式語言,如今是最常用的程式設計語言之一,舉凡Amazon、YouTube、Google、Yahoo!、NASA等大型企業和組織也青睞採用Python開發各種工具。Python的語法簡潔易讀,是少數既適合程式初學入門,且廣泛用於大數據處理∕深度學習等高階科學計算應用,也能在拇指大小的微電腦控制板運作的全領域、通用型程式語言。
本書以圖解、實作為出發點,除第一章的程式語言基礎、文字命令操作、安裝Python與程式編輯環境,每個章節都有實例與詳細圖解,帶領讀者學習Python程式設計。
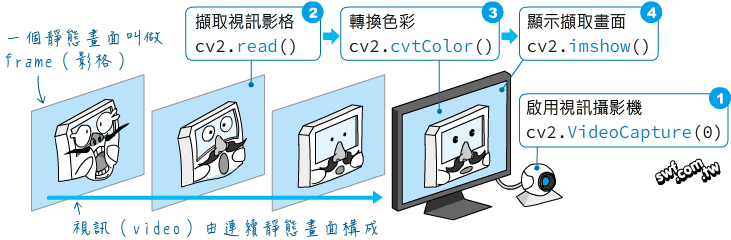
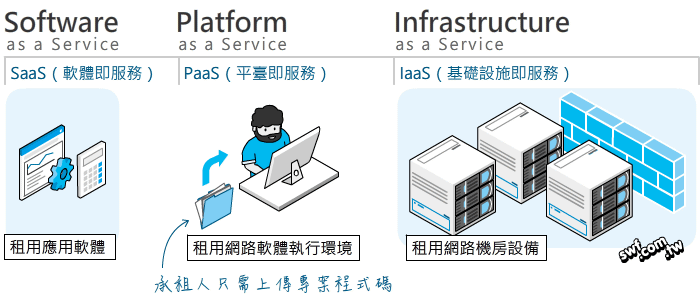
在許多實作應用的場合,光是了解程式語法是不夠的,像建構網路應用程式,還需要具備網路、防火牆、資料庫系統、租用並在雲端空間佈署應用程式…等概念,本書也針對這些基礎做了全方位的說明。
某些Python入門書籍沒有觸及的部分,例如:物件導向程式設計,因為很重要,所以筆者也用幾個淺顯實用的案例圖解說明。
《超圖解Python程式設計入門》章節大綱
第1章 認識Python程式語言
第2章 變數與條件判斷程式
- 規劃與製作問答題測驗程式
- 改變程式流程的if條件式
- 處理字串資料
- 格式化字串
第3章 列表、迴圈與自訂函式
- 儲存多筆相關資料的列表(list)
- 使用迴圈執行重複作業
- 使用 for…in 讀取序列結構資料
- 建立自訂函式

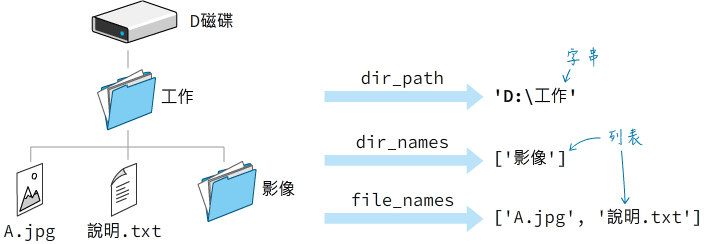
第4章 操作資料夾與文件:同步備份檔案
- 使用os程式庫操作檔案
- 使用argparse套件處理命令參數
- 嘿 Python~現在幾點?
- 直接執行 Python 程式檔
- 「可變」與「不可變」的資料類型和 Tuple(元組)
第5章 建立命令行工具:下載YouTube影片
- YouTube影音的Codec與下載視訊
- 將影片存入系統的預設路徑:辨別系統平台
- 使用 set(集合)建立不重複的選項列表
- 資料排序
- 使用try…except捕捉例外狀況
- 使用 FFmpeg 轉換多媒體檔案格式
第6章 自動收集網路資訊
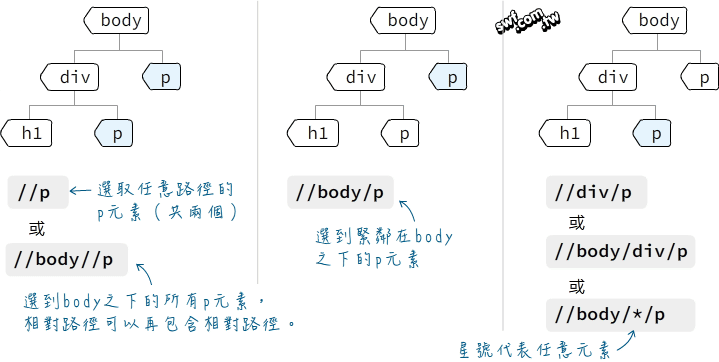
- 認識網頁與HTML
- 認識瀏覽器操控工具:Selenium
- 使用XPath語法選定HTML元素
- 認識查詢字串
第7章 儲存檔案:純文字檔、CSV檔與Google試算表
- 使用字典(dict)儲存結構化資料
- 在本機電腦儲存資料
- 讀寫CSV檔
- 使用Google雲端試算表儲存資料
第8章 建立自訂類別
- 自訂類別:遠離義大利麵條
- 儲存試算表資料的自訂類別
- 網路應用程式訊息交換格式:XML與JSON
- 儲存Python原生資料:pickle

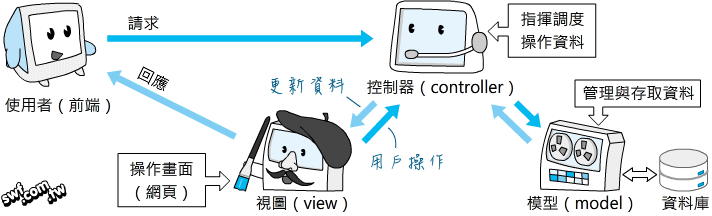
第9章 使用Flask建置網站服務
- 認識HTTP通訊協定
- Flask網站應用程式設計
- 存取靜態網頁檔
- 認識樣板與樣板引擎
- 處理表單
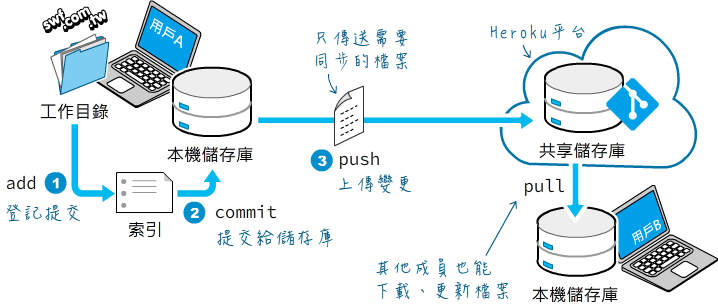
第10章 佈署網站到雲端空間
- 建立虛擬環境
- 佈署Flask網站程式到雲端平台
- 認識程式原始檔版本管理工具與Git
- 安裝與初設 Git 前端工具
- 設置Heroku CLI與發布檔案
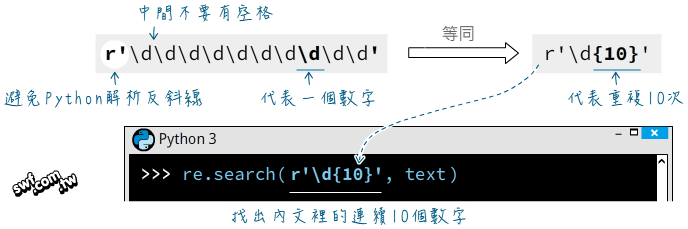
第11章 多執行緒下載檔案、規則表達式以及定時執行工作排程
- 透過Python程式發出HTTP請求
- 藉由MIME類型篩選檔案格式
- 規則表達式
- 下載JavaScript產生的動態內容
- 多執行緒同時下載多個檔案
- 定時執行程式碼
第12章 留言板網站應用程式
- 規劃資料表結構
- 產生SQLite資料庫檔案與操作資料
- 新增留言的表單網頁
- 認識 Cookie 和 Session
- 管理員登入

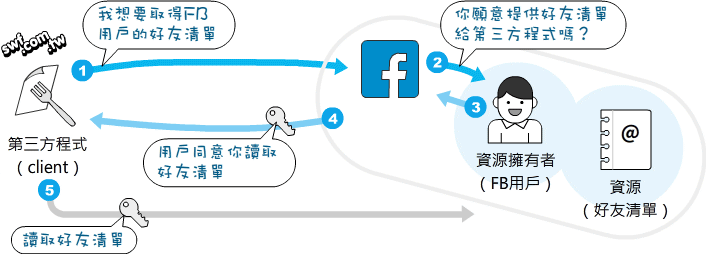
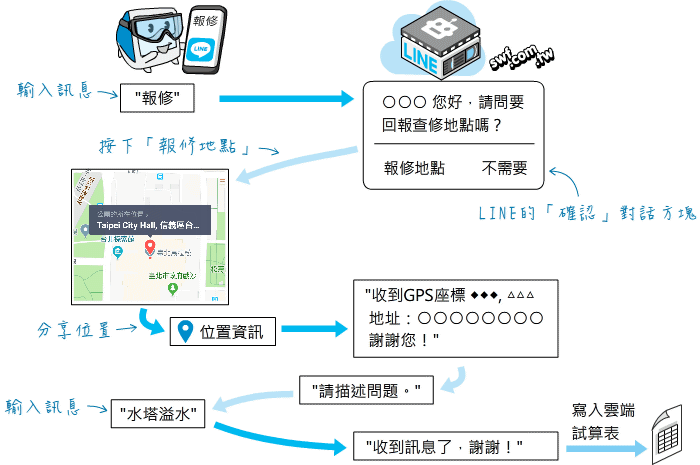
第13章 打造 LINE 聊天機器人
- LINE bot 聊天機器人程式開發
- LINE 線上報修
- 建立 LINE 圖文選單
第14章 影像處理與人臉辨識
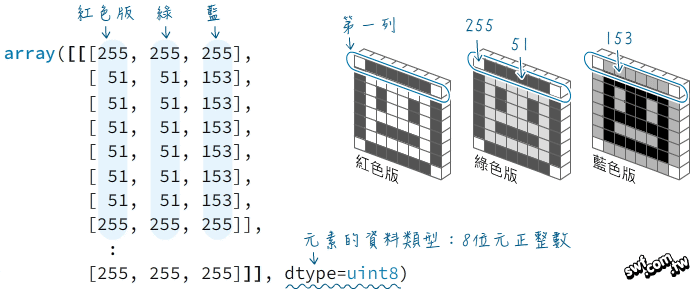
- NumPy 與影像處理
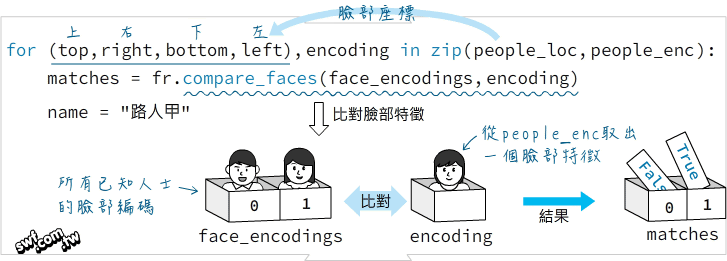
- 人臉識別程式
- OpenCV 即時人臉辨識
附錄A 列表生成式、裝飾器、產生器和遞迴
- 列表生成式 (list comprehension)
- 裝飾器語法說明
- 用產生器(generator)處理巨量資料
- 用遞迴改寫費式數列函式

附錄B LINE Bot物聯網:控制家電開關
- 從 MicroPython 控制板發送 LINE 訊息
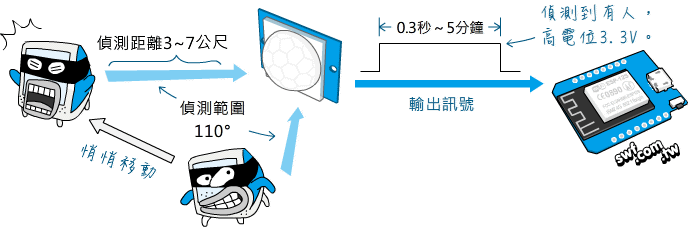
- PIR人體感應器
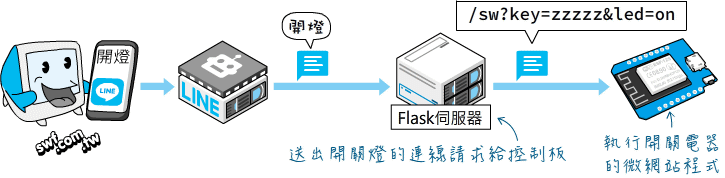
- 從 LINE 開關燈
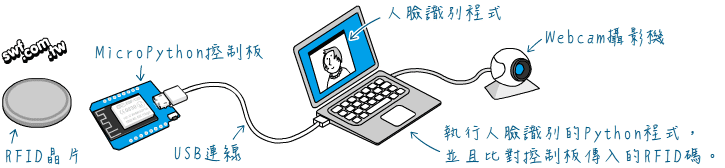
附錄C 人臉識別+RFID 門禁系統實驗
關於B-21頁,將檔案上傳esp8266的部分要如何完成前置作業呢?
請在電腦上執行:
pip install adafruit-ampy
安裝ampy工具程式,即可上傳MicroPython程式到控制板。
thanks,
jeffrey
老師您好,
請教當我在執行ch4_8.py時,刻意將src放置不存在的路徑
出現了以下的訊息(有幾次沒有出現此錯誤訊息). 找不出原因, 請老師幫忙,謝謝
Traceback (most recent call last):
File “ch4_8.py”, line 17, in
print(‘”{}” 不是資料夾路徑!’.format(src))
NameError: name ‘src’ is not defined
底下的錯誤訊息代表’src’變數未定義。
NameError: name ‘src’ is not defined
src源自第15行的路徑參數值,如果你把它移到其他地方,這個變數值就不存在了。
thanks,
jeffrey
老師您好,
於Python網站進行下載時無法下載,可否煩請協助
請問是哪個Python網站?
thanks,
jeffrey
老師您好,
今天跟著書裡說明,試著使用pytube下載Youtube
(上週前有成功下載)
但今日卻連影片的名稱(yt.title)都無法取得
得到了一個 base_js = get_ytplayer_config(html)[\”assets\”][\”js\”]
KeyError: \’assets\’
這樣的回應
請問應該如何修改呢?
了解,應該是被YouTube封鎖了,最近有些下載YouTube影片相關的開放原始碼專案都被移除了,我不確定有沒有轉圜的餘地,這一章的單元我會在部落格上替換成其他內容。
11/4更正:目前改用PyTube程式庫即可解決,請參閱「YouTube影片下載(六):改用PyTube程式庫解決執行錯誤」這篇貼文
thanks,
jeffrey
老師您好
我在執行第10章的 ssh -R 80:localhost:80 serveo.net
出現ssh: connect to host serveo.net port 22: Connection refused
已經安裝OpenSSH 請問要怎麼解決
我剛剛測試,發現serveo.net網站掛了,請改用ngrok。
thanks,
jeffrey
最近又新的PyTube程式庫,好像也不能使用了,不知道是不是youtube又擋掉了….
請執行底下的命令更新pytube,剛剛測試更新到目前最新版(10.8.2)沒問題。
pip install pytube –upgrade
thanks,
jeffrey
老师您好,
我尝试使用mac运行5-28的ffmpeg:
首先
pip install ffmpeg
成功,然后直接
ffmpeg -i xxx.mp4
错误
command not found: ffmpeg
请问怎么解决?
您好,那个错误信息代表你的电脑没有安装FFmpeg,请到官网下载安装:
https://ffmpeg.org/download.html#build-mac
thanks,
jeffrey
請問”超圖解 Python 程式設計入門”本書會有改版計畫嗎?謝謝
目前沒有改版計畫,但再印時會修訂錯誤並新增部落格文章的連結,像是:
佈署Python Flask網站留言板應用程式到Heroku + PostgreSQL資料庫系統
在Heroku雲端平台使用Redis記憶體資料庫
Python Flask SQLAlchemy網站資料庫分頁程式與介面製作
謝謝!
老師您好,我想讓板子連動到Line發訊息,嘗試使用書本後面提到的urequest程式庫,但一直跑出這個錯誤查了好幾天了都找不到如何解決,開老師的範例程式bot_sw.py執行後也是這樣
Traceback (most recent call last):
File “”, line 20, in
File “/lib/urequests.py”, line 112, in get
File “/lib/urequests.py”, line 100, in request
File “/lib/urequests.py”, line 60, in request
TypeError: extra keyword arguments given
請問老師要怎麼解決呢
請問你的MicroPython韌體是那一版?
我剛剛燒錄最新版本測試:
https://micropython.org/download/esp8266-1m/
它沒有內建urequests,需要讓板子聯網(修改boot.py檔),然後在REPL命令介面輸入底下兩個命令安裝程式庫:
import upip
upip.install(‘micropython-urequests’)
安裝完畢後,在ESP8266上執行書本的bot_sw.py檔,沒有問題。
謝謝老師,有解決了,雖然我也不知道是韌體版本還是urequests的問題,原本我是燒錄ESP8266 with 2MiB+ flash的最新版本然後用thonny內建的Manage packages安裝micropython的Latest stable version: 0.9.1版本,但一直跑出我上面po的那個問題,後來重新燒錄了1MiB的版本後使用命令:
import upip
upip.install(‘micropython-urequests’)
他自動安裝了micropython-urequests 0.6版本,神奇的是程式就可以執行了!
thanks,
justin
感謝告知!
老師您好
我照著 2-8 頁操作, 以下為所出現的畫面。
C:\Users\ADMIN>import keyword
‘import’ 不是內部或外部命令、可執行的程式或批次檔。
C:\Users\ADMIN>print(keyword.kwlist)
無法初始化裝置 PRN
請問要怎麼解決
你好,請先輸入python,啟動python環境才能輸入程式敘述。
請問 11-33 ~ 11-34頁
最後要測試多執行緒下載類別的程式
該程式寫法書本上有,但電子檔沒給
所以我手打後執行,去載入thread_download的Download函數
但執行後沒有效果,也沒有提示任何錯誤
想問原因?
我是使用visual studio code去執行的
本前面的範本
download_img.py我執行都有成功下載圖片
但唯獨11-33~11-34頁的不行
ok老師我後來懂了,11-33~11-34頁的代碼要修改成跟download_img.py一樣
要偽裝成瀏覽器,並且要設定http標頭,這樣才能正常下載,不然網頁會出現錯誤
Not Acceptable!
An appropriate representation of the requested resource could not be found on this server. This error was generated by Mod_Security.
而不給存取下載,
我已可以成功下載了
抱歉,因為這個網站伺服器會抵擋沒有User-Agent標頭欄位的請求,我自訂名叫“PYTHON3”的User-Agent,修改後的主程式碼命名成main.py,存入書本範例ch11\theads資料夾:
from lxml import html import requests as req from thread_download import Download # 引用自訂類別 url = 'http://swf.com.tw/download/' # 包含下載檔案的網頁 page = req.get(url, headers={"User-Agent": "PYTHON3"}) dom = html.fromstring(page.text) links = dom.xpath('//a/@href') files = [] # 儲存下載檔案的列表 for href in links: if not href.startswith('http'): href = url + href h = req.head(href, headers={"User-Agent": "PYTHON3"}) MIME = h.headers.get('content-type') if (h.status_code == 200) and ((MIME is None) or ('html' not in MIME)): print(href) files.append(href) # 把檔案加入下載列表 dw = Download(files) # 宣告「多執行緒下載」類別物件 dw.start() # 開始下載列表裡的檔案老師我發現書本後面B-2頁的物聯網(internet of Thongs,簡稱IoT)打錯了
應該是Things,Thong貌似是丁字褲的意思..
感謝你讓我認識新單字 😀
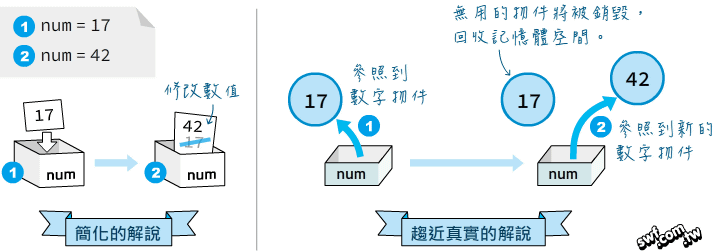
老師,感謝您上次的解答。我算是剛學程式語言的新手(但我運維很有實力),我想詢問下: 就是我看了很多的程式範本,發現很多class()或function(),他們在被主程式呼叫時,都會放到不同的變量中,之後再被print給顯示於螢幕上。但我有疑問,譬如假設A類別中有a函式又有aa屬性,那A.a.aa()就可用print列印出來了,那為什麼課本的範本,都常常把這些又多放到一個變數裡,然後再用print顯示呢?( 譬如B = A.a.aa()然後print(B) ) 為何要多此一舉?是因為這樣執行效率會更好嗎?還是說這樣能增加識別度?
直接印print(A.a.aa())不是能更好識別嗎?若印print(B),那還要去找B來自於哪裡,增加了複雜度(要找來找去.一直轉換來轉換去的)
沒錯,有時為了簡化程式碼或者增加可讀性,可以把物件存入變數,相當於替它設定一個「暱稱」。像網頁上的超連結標籤,可能位於不同層次結構,統一將它們稱作「超連結」。存取記憶體的操作幾乎對運算效能的影響低到可以忽略。
求課本P12-24頁的nl2br函式的解釋:
u’\n\n’的u是什麼意思?
u’%s’ % p.replace() 是什麼意思?
u開頭的字串代表Unicode編碼字串,主要用於Python 2,因為Python 3預設採用Unicode,所以可以省略。
字串資料後面的百分比(%)符號,用於串接格式化字串的資料(元組格式),跟f字串的作用類似。例如:
print(“%s一顆%d元” % (“茶葉蛋”, 10))
顯示:
茶葉蛋一顆10元
感謝老師回復
另想再詢問下
1). ch12章的管理者帳密是多少(要登入到課本範本的留言板後台用的),我有用sqllite去看db內的帳密,但是密碼被sha256加密了,所以不知道登入後台的帳號密碼
2). 另向再詢問下之前課本p12-24頁的,u’\n\n’ 的\n\n是什麼意思?為什麼要兩個\n ?
1. 請參閱12-13頁,在Python環境重新產生一個密碼雜湊值,取代掉SQLite裡的舊資料。
2. 替換<br>使用一個’\n’產生一個斷行;替換<p>則使用’\n\n’產生兩個斷行,或者說一個「空行」。
您好,我在測試超圖解Python程式入門的7-1,發現雖然成功執行爬蟲,但只能爬到yahoo拍賣,然後就停止了,看程式碼本身應該沒出錯,所以想請教如何處理,謝謝!
因為購物網站調整了網頁結構,以蝦皮購物網站為例,這個網頁:
https://shopee.tw/search?keyword=神臂鬥士&page=0&sortBy=ctime
原本的商品標題的XPath路徑是:
//div[contains(@class,’shopee-search-item-result__item’)]/div/a/div/div[2]/div[1]/div
現在改成:
//div[contains(@class,’shopee-search-item-result__item’)]/a/div[1]/div[1]/div[2]/div[1]/div[1]/div[1]
商品價格的XPath路徑則改成:
//div[contains(@class,’shopee-search-item-result__item’)]/a/div[1]/div[1]/div[2]/div[2]/div[1]
因為網站隨時可能調整內容,請參閱6-30頁的說明,自行找出對應資料的XPath試試。
謝謝老師回覆!我稍後再作嘗試,另外想請問爬蟲的資料筆數是否有上限?因為我發現明明網上有幾百到過千筆資料,但爬蟲最多只能抓到幾十筆,謝謝!
沒有,因為我只關心最新刊登的商品資料,因此只擷取第1頁。
老師您好,剛剛成功把露天的路徑完成,但蝦皮按照您的路徑仍然無法使用,謝謝!
‘url’:’https://shopee.tw/search?keyword={key}&page=0&sortBy=ctime’,
‘title_path’:”//div[contains(@class, ‘shopee-search-item-result__item’)]/a/div[1]/div[1]/div[2]/div[1]/div[1]/div[1]”,
‘price_path’:”//div[contains(@class, ‘shopee-search-item-result__item’)]/a/div[1]/div[1]/div[2]/div[2]/div[1]”,
‘link_path’:”//div[contains(@class, ‘shopee-search-item-result__item’)]/a”
測試程式的時候,建議縮小範圍,像「Yahoo!拍賣」爬蟲程式測試無誤,其他網站不行,代表主程式沒有問題,那問題就出在HTML元素的路徑。
我先測試執行第6章的yahoo.py,只擷取雅虎拍賣資料,沒有問題。
接著把selenium更新到最新版,測試發現兩個問題,第一個問題屬於「語法即將過時」,也就是未來版本可能不再支援此語法的”DeprecationWarning”警告訊息:executable_path has been deprecated selenium python。
意思是將來的某個selenium版本可能不再支援webdriver的executable_path(絕對路徑)語法。
第二個問題是,從3.4.0版本之後,selenium刪除了find_elements_by_xpath()方法,所以程式執行時出現”‘WebDriver’ object has no attribute ‘find_elements_by_xpath’(WebDriver物件沒有find_elements_by_xpath屬性)”錯誤,要改用find_elements()以及find_element()方法:
相關說明可參閱selenium官方說明文件:https://selenium-python.readthedocs.io/locating-elements.html
解決第一個webdriver的語法過時問題,請在程式開頭引用Service模組:
from selenium.webdriver.chrome.service import Service
然後把這兩行:
driver_path = “C:\\webdriver\\chromedriver.exe”
driver = webdriver.Chrome(driver_path, options=option)
改成:
s = Service(“C:\\webdriver\\chromedriver.exe”) # 建立「服務」
driver = webdriver.Chrome(service=s, options=option)
解決第二個find_elements_by_xpath()方法的問題,請在程式開頭引用By模組:
from selenium.webdriver.common.by import By
然後把find_elements_by_xpath()敘述:
titles= driver.find_elements_by_xpath(title_path)
prices= driver.find_elements_by_xpath(price_path)
links= driver.find_elements_by_xpath(link_path)
改成:
titles= driver.find_elements(By.XPATH, title_path)
prices= driver.find_elements(By.XPATH, price_path)
# By.XPATH等同”xpath”
links= driver.find_elements(“xpath”, link_path)
完整的蝦皮購物網站的測試程式碼如下:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from urllib import parse search_key=parse.quote('神臂鬥士') # 商品關鍵字 url='https://shopee.tw/search?keyword={key}&page=0&sortBy=ctime' url=url.format(key=search_key) # 蝦皮拍賣網址 # driver_path = "C:\\webdriver\\chromedriver.exe" s = Service("C:\\webdriver\\chromedriver.exe") option = webdriver.ChromeOptions() option.add_argument('headless') # 新增隱藏(無頭)參數 # driver = webdriver.Chrome(driver_path, options=option) driver = webdriver.Chrome(service=s, options=option) driver.implicitly_wait(10) driver.get(url) title_path = "//div[contains(@class,'shopee-search-item-result__item')]/a/div[1]/div[1]/div[2]/div[1]/div[1]/div[1]" price_path = "//div[contains(@class,'shopee-search-item-result__item')]/a/div[1]/div[1]/div[2]/div[2]/div[1]" link_path="//div[contains(@class,'shopee-search-item-result__item')]/a" titles= driver.find_elements(By.XPATH, title_path) prices= driver.find_elements(By.XPATH, price_path) # By.XPATH等同"xpath" links= driver.find_elements("xpath", link_path) total = len(titles) print('商品數量:', total) print('='*60) # 顯示商品和價格 size = 5 if total>=5 else total index = 0 for title, price, link in zip(titles, prices, links): print(title.get_attribute('textContent') + "\n" + price.text + "\n" + link.get_attribute('href')) print('-'*60) index += 1 if index == size: break driver.quit()我測試過老師提供的程式碼,單獨運行蝦皮是成功的,路徑沒問題,但將路徑貼回用字典集合三個網站的版本就不行,但其他兩個網站都正常運作,謝謝。
剛剛測試執行沒問題:
{ 'url':'https://shopee.tw/search?keyword={key}&page=0&sortBy=ctime', 'title_path':"//div[contains(@class,'shopee-search-item-result__item')]" "/a/div[1]/div[1]/div[2]/div[1]/div[1]/div[1]", 'price_path':"//div[contains(@class,'shopee-search-item-result__item')]" "/a/div[1]/div[1]/div[2]/div[2]/div[1]", 'link_path':"//div[contains(@class,'shopee-search-item-result__item')]" "/a" }執行13-14的 python src\bot.py 時
顯示
Traceback (most recent call last):
File “C:\linebot\src\bot.py”, line 1, in
from flask import Flask, request, abort
File “C:\linebot\env\lib\site-packages\flask\__init__.py”, line 19, in
from jinja2 import Markup, escape
ImportError: cannot import name ‘Markup’ from ‘jinja2’ (C:\linebot\env\lib\site-packages\jinja2\__init__.py)
都有照前面步驟進行
排除不了錯誤
麻煩老師幫我看看 謝謝!
那個錯誤訊息是因為Flask的jinja2移除了Markup模組,請依照書本範例的requirements.txt安裝虛擬環境的套件,或者手動指定jinja2的版本,像這樣:
pip install jinja2==3.0.3 –force-reinstall
或
python -m pip install jinja2==3.0.3 –force-reinstall
執行13-14的 ssh -R 80:XXX.XXX.XX.XX:80 serveo.net 時
顯示
ssh: connect to host serveo.net port 22: Connection timed out
上網查處理方法還是無法自行debug
故來請教老師看看這部分該怎麼處理
那一排X是自己的本機位址嗎?
謝謝老師
因為serveo.net網站掛了,你可以在命令提示字元或終端機輸入:
ping serveo.net
測試連線,它將傳回Request timed out.(請求逾時)。
請改用10-15頁的ngrok,謝謝。
老師好
稍早換ngrok依照流程生成網址後
回到LINE Developers的Webhook URL輸入給的網址/callback後,顯示:
A timeout occurred when sending a webhook event object
去cmd輸入ping ngrok.io依然顯示:
Ping ngrok.io [XX.XX.XXX.XX] (使用 32 位元組的資料)
要求等候逾時。
要求等候逾時。
要求等候逾時。
要求等候逾時。
不能確定到底是哪邊出了問題…
你要使用ngrok產生的網域,而不是ngrok.io,像下圖紅色框線包圍的部分是我的本機電腦對外的網域,用ping測試時,要輸入這個網域。
在LINE開發人員網頁輸入網址時,請輸入這個網域,前面要加上“https://”,後面加上你的Python Flask的callback路徑,也就是”/callback”,如13-16頁所示。
假使你的ngrok依然無法順利連讓,請先在ngrok.com註冊帳號,進入這個網頁:
https://dashboard.ngrok.com/get-started/setup
即可在它的步驟2,看到如10-17頁的驗證碼命令.
老師好,請問一下c-5頁中上傳MFRC522模組驅動程式到控制板這方面,是否要參閱才可以執行?因為我是用usb,但在cmd裡無法直行ampy –port com3 put mfrc522.py的指令,後面用PuTTY 也讀取不到D1控制板,每個serial也都嘗試過了。謝謝老師。
請問你的D1開發板有事先燒錄MicroPython韌體嗎?
若沒有,請點擊這篇貼文:
使用Thonny Python IDE編寫MicroPython程式(一)
謝謝老師,我去嘗試看看!
老師好,我燒錄之後顯示這樣
PROBLEM IN THONNY’S BACK-END: Internal error (thonny.plugins.micropython.mp_back.ManagementError: Script produced errors).
See Thonny’s backend.log for more info.
You may need to press “Stop/Restart” or hard-reset your MicroPython device and try again.
Process ended with exit code 0.
請問D1 mini 板可以燒入esp8266的韌體嗎?
可以,請在這個網頁下載ESP8266的MicroPython韌體:
https://micropython.org/download/esp8266/
剛剛測試燒錄這個1.19.1版沒問題:
https://micropython.org/resources/firmware/esp8266-20220618-v1.19.1.bin
開發版購買,請問老師最近從天龍購買此書本,那邊有開發版可以買呢?謝謝
請問你指的是附錄的WEMOS D1 mini (ESP8266) 開發板嗎?網拍買得到,旗標科技在蝦皮也有設買場,也可以點擊這個《超圖解 Python 物聯網實作入門:使用 ESP8266 與 MicroPython》零件清單(/?p=1141)中的連結詢問。
老師您好,我在做第13章line bot的時候,用cmd 啟動bot.py時都會顯示以下錯誤訊息。把相對應的函式庫資料夾拉到編譯器下的資料夾又會出現新的錯誤訊息,請問可以怎麼解決?
Traceback (most recent call last):
File “src\bot.py”, line 1, in
from flask import Flask, request, abort
File “D:\python\lib\site-packages\flask\__init__.py”, line 19, in
from jinja2 import Markup, escape
ImportError: cannot import name ‘Markup’ from ‘jinja2’ (D:\python\lib\site-packages\jinja2\__init__.py)
我按照書本13章的內容重新操作一遍,Line bot的requirements.txt當中的Flask版本設成1.0.2,請改成2.0.3,或者,在虛擬環境中執行pip uninstall命令移除Flask和Jinja2:
輸入命令後,它會詢問你是否真要刪除它,請按下y和Enter鍵(它會再跟你確認是否要移除Jinja2)。
(env) PS D:\line\src> pip uninstall Flask Jinja2 Found existing installation: Flask 1.0.2 Uninstalling Flask-1.0.2: Would remove: d:\line\env\lib\site-packages\flask-1.0.2.dist-info\* d:\line\env\lib\site-packages\flask\* d:\line\env\scripts\flask.exe Proceed (Y/n)?舊版移除完畢後,再輸入底下命令安裝Flask,它就會自動下載並安裝新版Flask和Jinja2:
再次啟動bot.py,就能順利執行了。
好的,謝謝老師,晚一點試試看。
不客氣
老師您好,pip新的版本後,重新啟動出現以下錯誤訊息:
Traceback (most recent call last):
File “src\bot.py”, line 2, in
from linebot import LineBotApi, WebhookHandler
File “d:\LINE\env\lib\site-packages\linebot\__init__.py”, line 22, in
from .api import ( # noqa
File “d:\LINE\env\lib\site-packages\linebot\api.py”, line 23, in
from .http_client import HttpClient, RequestsHttpClient
File “d:\LINE\env\lib\site-packages\linebot\http_client.py”, line 21, in
import requests
File “d:\LINE\env\lib\site-packages\requests\__init__.py”, line 43, in
import urllib3
File “d:\LINE\env\lib\site-packages\urllib3\__init__.py”, line 42, in
“urllib3 v2.0 only supports OpenSSL 1.1.1+, currently ”
ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the ‘ssl’ module is compiled with ‘OpenSSL 1.1.0j 20 Nov 2018’. See: https://github.com/urllib3/urllib3/issues/2168
有到github網站看,整體看下來感覺是因為OpenSSL的問題?(但在urllib3下的__init__.py,也找不到OpenSSL 1.1.0j 的相關程式碼)
也有看到版本至少要3.7,還是是因為編譯器版本?目前是有載3.7.3及3.12.1,VS Code及cmd的編譯器都是用3.7.3,但如果把VS Code的版本換成3.12.1,又會變成src\bot.py的前三行(import)會顯示”無法解析匯入”
想請問老師怎麼解決?
Python執行環境(直譯器)更新到3.12.1之後,你有重新建立虛擬環境嗎?
老師,想請問一下,VS Code的編譯器已經改成3.12.1,cmd也重新啟動了,python -V還是顯示python 3.7.3,python -3.12.1 -V也還是不行,要怎麼切換?還是直接把3.7.3卸載?
老師您好,我把3.7.3卸載後,重新安裝3.12.1,也把本來的env砍掉重建,用cmd啟動顯示以下錯誤訊息
Traceback (most recent call last):
File “d:\LINE\src\bot.py”, line 1, in
from flask import Flask, request, abort
File “d:\LINE\env\Lib\site-packages\flask\__init__.py”, line 7, in
from .app import Flask as Flask
File “d:\LINE\env\Lib\site-packages\flask\app.py”, line 28, in
from . import cli
File “d:\LINE\env\Lib\site-packages\flask\cli.py”, line 18, in
from .helpers import get_debug_flag
File “d:\LINE\env\Lib\site-packages\flask\helpers.py”, line 16, in
from werkzeug.urls import url_quote
ImportError: cannot import name ‘url_quote’ from ‘werkzeug.urls’ (d:\LINE\env\Lib\site-packages\werkzeug\urls.py). Did you mean: ‘unquote’?
在VS Code,import那三行還是顯示無法解析匯入,該怎麼解決?
咦?我執行沒問題ㄟ…
Windows系統的Python預設安裝路徑是:
我的電腦先後安裝了Python 10.x和12.x版,所以這個路徑底下會有兩個資料夾。你可以按照移除應用軟體的方式,從Windows系統控制面板的「已安裝的應用程式」,移除不需要的Python版本。
你可以保留多個Python版本,預設啟動哪一個,由Windows的環境變數決定。請查看你的電腦的「使用者環境變數」或「系統環境變數」裡的Path變數,裡面會有Python的路徑設定,像底下這個值代表當你在終端機執行Python,它將啟動Python 3.12.x版:
把它改成其他Python安裝路徑,即可改變預設的啟動版本(終端機視窗要關閉再重開)。
你可以透過py命令,加上”-版本”參數來啟動指定版本的Python,例如,指定啟動3.10.x版:
或者,指定啟動3.12.x版:
同樣地,執行底下的命令,將會在目前的路徑新增一個Python 3.10.x版的”env”虛擬環境:
新建完畢後,用VS code開啟此資料夾,即可從工作列選擇虛擬環境的Python直譯器(解譯器)版本。
老師您好,我把flask和werkzeug函式庫重新下載後就沒有出現錯誤訊息了。但變成出現這段訊息
* Serving Flask app ‘bot’
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:80
* Running on http://192.168.XXX.XXX
Press CTRL+C to quit
* Restarting with stat
* Debugger is active!
* Debugger PIN: XXX-XXX-XXX(有9碼數字)
這樣是正常的嗎?
VS Code的1~3行還是’無法解析匯入'(還是因為我存在行動硬碟的關係?)
另外,要存取本機80埠也出現問題
ssh: connect to host serveo.net port 22: Connection refused
是有查到如果是用wifi分享器的話,cmd ipconfig顯示的位址是分享器分配的,會有關嗎?
那個警告訊息是正常的,請參閱9-6頁。你的程式碼前三行出現import錯誤,代表你的虛擬環境沒有安裝對應的程式庫,請問你有依照13-11頁底下的說明操作嗎?
Python Flask程式執行後,我使用ngrok轉發本機網站,操作說明影參閱10-15。這時你的電腦本機位址,對外將變成這個網址:
https://c406-121-XXX.ngrok-free.app
像這樣:
用你的Line帳號登入程式開發網頁,找到你的專案頁面的Webhook欄位,輸入回呼網址:
https://c406-121-XXX.ngrok-free.app/callback
像這樣:
按下Verify驗證,它應該呈現這樣的畫面,代表驗證成功:
而VS Code的終端機也會出現callback被呼叫的訊息,像這樣:
老師,如果我重新pip requirements.txt(Flask版本已經改成2.0.3,gspread==3.1.0、line-bot-sdk==1.8.0、oauth2client==4.1.3,有版本要改嗎?),再用cmd重新啟動src\bot.py,又會顯示剛開始的錯誤訊息(1月8號、1月12號的),重新pip flask werkzeug函式庫後就可以正常啟動(今天下午1:06的訊息),所以是要以requirements.txt的版本為準還是重新pip flask werkzeug函式庫的?(VS Code都一樣會顯示無法解析匯入)
網站伺服器的部分,不管是用ngrok、cmd、powershll輸入ngrok http 80都無法轉發本機位址,會跑出類似help的訊息。用cmd ssh -R 80:設定看到的IPv4位址:80 serveo.net是可以跑出網址,但https://後面是亂碼,貼到line的webhook按Verify驗證,不會跳出success或error的視窗,但cmd ssh -R跑出來的網址下面會多一行,看起來是line伺服器的回覆,這樣正常嗎?
我猜想你輸入的ngrok命令前面沒有加上”./”(參閱10-17頁),至於serveo.net跑出網址是亂碼,我猜想你指的是它隨機生成的網域名稱,那是正常的。
以範例程式的相容性來說,只需要修改requirements.txt的Flask版本,一個虛擬環境只需要執行一次,它的作用就像執行一連串pip install,幫你安裝指定的程式庫。日後若要改成其他版本,你可以先執行pip uninstall移除它再重裝,或者執行upgrade參數升級(參閱5-6頁)。
老師,VS Code開啟bot.py,前三行還是會顯示”無法解析匯入”,這三行要的函式庫是引用這兩個路徑下的,對嗎?
D:\LINE\env\Lib\site-packages\flask
D:\LINE\env\Lib\site-packages\linebot
但在env執行bot.py是可以的,想請問怎麼解決?
另外,在LINE Developers的webhook url可以了,按verify有顯示success
請問你的VS Code,有設定Python的執行環境是 “D:\LINE\env\” 嗎?
老師,目前都可以了,VS Code沒有出現錯誤訊息,cmd也可以啟動bot.py,加入line好友傳訊息也都會回傳(13-20),非常感謝老師。
想問一下老師,早上的時候,在cmd執行ssh -R 80:xx.x.xxx.xxx:80 serveo.net是可以的,後來改檔案斷線後要再執行時,跑出以下錯誤訊息:ssh: connect to host serveo.net port 22: Connection refused,但現在又可以執行,有試著以系統管理員執行stop-service sshd再開啟,但還是不行,想請問老師可以怎麼解決?
還想問一下老師,做第13章前,一定要先做第10章嗎?
感謝告知!我覺得serveo.net比較不穩定,所以我後來都使用ngrok。
第10章的內容說明在雲端佈署web應用程式,可說是第9章的延續;在本機測試web應用程式,不必先閱讀第10章。
你好,7-1 好像不能执行爬虫,获取不到资料,虾皮好像是需要而外做个执行登入程序才能获取资料。
想请教该如何处理呢,谢谢!
对,虾皮网站有两步骤验证,登入之后,它会要求输入短信(简讯)密码,所以无法单独依靠selenuim自动完成…或许可以尝试先在浏览器登入虾皮,再让程式控制目前的浏览器,但这样就不是全自动化作业了。
您好!!目前在操作selenium一直無法順利完成,試過許多方式重新下載selenium或是webdriver版本更新都是過還是不行正常使用
你好,請參閱這個回應:解決webdriver的問題(/?p=1205&cpage=2#comment-990895),謝謝!
科技带来更多机会請造訪我們的網站 Telkom University Jakarta