本文的OrangePi 5 Max開發板由Orange Pi的Nova和Steve贊助提供,特此感謝!
本文將使用OpenCV + YOLO視覺物件偵測套件,測試香橙派5 Max的Rockchip (瑞芯微)RK3588晶片內建的3核心NPU(類神經網路處理器)的效能,並說明如何在執行Ubuntu作業系統的香橙派上,建置Python開發環境,把既有、已訓練好的YOLO物件偵測模型,從原本的PyTorch格式(.pt檔),轉換成Rockchip系列處理器NPU專屬的RKNN格式(.rknn檔)。
YOLO是先進、易用且廣受歡迎的電腦視覺物件偵測開源程式,可偵測靜態影像或視訊影片的內容,例如:標示特定物件(如:人、狗、汽車…等)出現的位置、分析人物肢體姿態、追蹤物件的移動路徑…等任務。
YOLO透過「模型檔」(相當於知識庫)賦予它分辨不同物件的能力,有些模型檔提供分辨植物病蟲害的功能,有些提供分辨口罩、安全帽等物件的功能。
YOLO本身提供了可分辨80種物件的模型檔,而且有不同的精確度和檔案大小可選,例如,yolo11n.pt模型檔,是用於YOLO第11版的奈米(nano,代表檔案最小)的模型,精確度低(比較容易偵測錯誤),但是對電腦的運算效能和記憶體大小的需求也最低。這些模型檔可在YOLO視覺物件偵測套件的網頁下載。
認識Rockchip的RKNN-Toolkit2工具套件
一般的YOLO模型檔(如:yolo11n.pt)可以在安裝YOLO套件的個人電腦,以及香橙派和樹莓派之類的開發板執行,但在香橙派和樹莓派上,YOLO都是用CPU進行推論,效能不佳。
為了提升YOLO在內建NPU的Rockchip晶片上的物件偵測速度,Rockchip公司提供了開源的RKNN-Toolkit2工具套件,讓開發人員把既有的YOLO模型檔(.pt檔)轉換成專屬的RKNN格式。
在Rockchip晶片上執行採用RKNN格式模型檔的YOLO程式,將能利用NPU加速推論,宛如在個人電腦上透過GPU加速。下圖是RKNN-Toolkit2工具套件的開源頁面:
下文將說明如何把RKNN-Toolkit2工具原始碼下載、安裝到香橙派5 Max,並用它轉換既有的YOLO模型檔。
這是RKNN-Toolkit2工具(以下簡稱「RKNN套件」)的目錄內容:

在”packages(套件)”中,可看到程式套件依處理器架構,分成”arm64”和”x86_64”兩種:
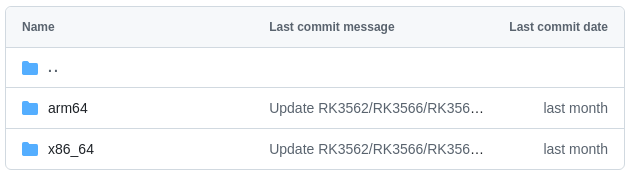
“x86_64”套件適用於Intel或AMD 64位元處理器的Linux電腦系統;”arm64”則是用於ARM處理器架構的Linux電腦系統,例如:執行Ubuntu系統的OrangePi 5 Max。
底下是arm64套件的內容,分成兩種檔案:純文字(.txt)的Python套件需求清單(requirements),以及預先編譯好的程式元件集合(.whl檔)。這兩種檔案也都依照開發環境的Python解譯器(CPython,在檔名中簡寫成cp)區分,安裝時,必須選擇符合自己電腦環境的版本。
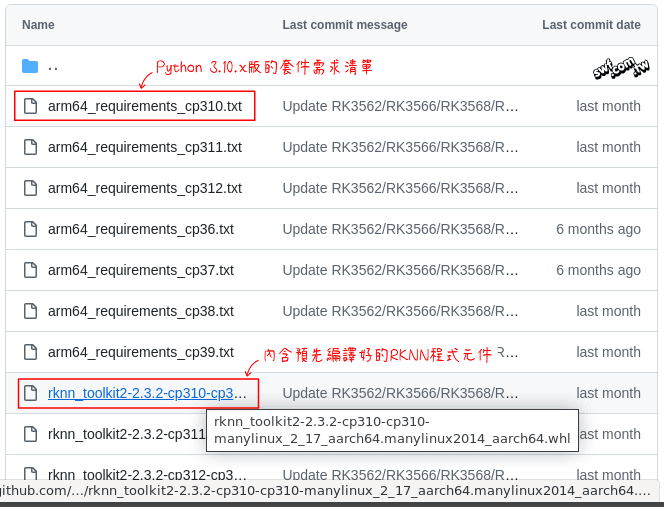
我安裝在香橙派5 Max的系統是Ubuntu 22.0.4 (Jammy),該系統預設安裝Python 3.10.x版,所以RKNN套件也要選擇安裝cp310版。
編譯程式元件的檔名,遵循PEP 425和PEP 491定義的標準Python wheel檔案命名慣例,格式如下:
{發行名稱}-{版本}(-{建置標記})?-{python標記}-{abi標記}-{平台標記}.whl
其中最重要的是支援的CPython版本,ABI意指“Application Binary Interface”(直譯為「應用程式二進位介面」)相當於編譯環境採用的CPython版本;“manylinux”,也就是”many Linux”,代表相容於多種主流Linux系統,例如:Ubuntu, Debian, Armbian,…等。

RKNN-Toolkit2工具的相依Python套件和版本
這是arm64_requirements_cp310.txt檔案的內容:

需要留意的是套件版本的範圍限制,新版套件可能會修改某些指令語法,導致程式碼不相容。若按照一般的Python套件安裝命令,例如,安裝numpy:
pip install numpy
它將安裝目前的最新版(2.2.x)。安裝某些套件時,該套件可能會一併安裝其他相依套件,例如,安裝OpenCV時,它會連帶安裝NumPy,而自動安裝的NumPy,也許不符合RKNN工具要求的<=1.26.4版。
設置Python虛擬環境以及安裝RKNN工具
為了避免不同專案的套件版本起衝突,可替它們設立專屬的虛擬環境。筆者將存放此專案的資料夾命名為‘yolo’。
在此yolo目錄中,執行底下命令建立名叫‘env’的虛擬環境。
python -m venv env
接著啟動虛擬環境:
source env/bin/activate
你可以先確認虛擬環境的Python版本:

下載預先訓練好的.pt模型檔
稍後將示範把“yolo11n.pt”檔轉換成RKNN格式,請先在終端機執行wget(下載檔案)命令,把yolo11n.pt下載到目前所在的‘yolo’目錄:
wget https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt
在Python虛擬環境下載與安裝RKNN Toolkit2工具
執行下列步驟,開始安裝對應的RKNN工具版本,底下示範以Python 3.10.x版為例。
1. 執行git clone命令,複製RKNN Toolkit2專案原始碼到此虛擬環境:
git clone https://github.com/airockchip/rknn-toolkit2.git
執行完畢後,虛擬環境的資料夾結構將是:

2. 切換到RKNN Toolkit2套件的”arm64”路徑:
cd rknn-toolkit2/rknn-toolkit2/packages/arm64/
3. 安裝指定Python版本所需的套件:
pip install -r arm64_requirements_cp310.txt
4. 安裝指定Python版本,預先編譯好的RKNN工具套件:
pip install rknn_toolkit2-2.3.2-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
安裝YOLO套件並排除Python套件版本衝突
轉換AI模型檔以及視覺物件偵測都要用到YOLO套件,所以要安裝它(Ultralytics是YOLO套件的幾個發行版的程式開發公司的名稱)。
pip install ultralytics
安裝YOLO套件時,它可能會移除之前安裝的舊版torch,然後安裝更新版本。例如,底下的訊息顯示移除了torch-2.2.0,然後安裝了torch-2.7.0,這與RKNN工具套件的需求(<=2.2.0,>=1.13.1)不同,因而產生版本衝突錯誤。
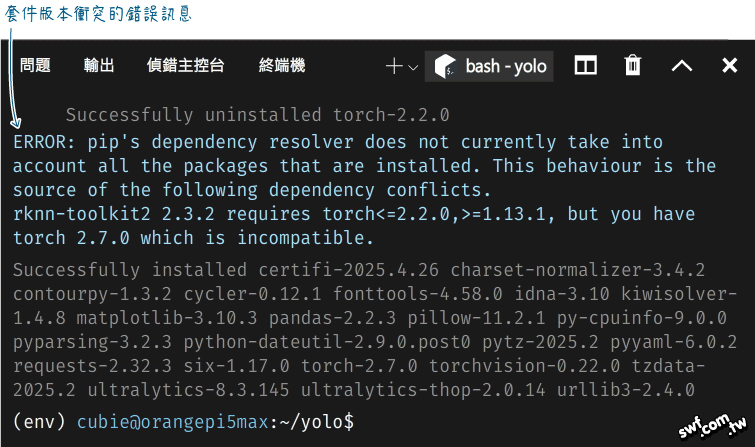
我們必須手動移除torch,以及相依的torchvision套件:
pip uninstall torch torchvision -y
再重新安裝指定版本:
pip install torch==2.2.0 torchvision==0.17.0
安裝完畢後,執行pip check命令,查看套件是否存在版本衝突問題,結果顯示沒有,代表程式開發環境設定好了。
把PT(PyTorch)模型轉成RKNN格式
終於可以開始轉換模型檔了!YOLO專案官網的「Rockchip RKNN 导出Ultralytics YOLO11 模型」貼文(簡體中文),完整介紹了轉換模型檔的原因,並且提供轉檔的Python程式。
請在src 資料夾新增一個負責轉換RKNN格式的Python檔案,筆者將它命名為pt2rknn.py。程式碼取自「Rockchip RKNN 导出Ultralytics YOLO11 模型」貼文:
from ultralytics import YOLO
# 載入YOLO11模型
model = YOLO("yolo11n.pt")
# 匯出 RKNN 格式的模型
# 'name'可以是這些型號的晶片:
# rk3588, rk3576, rk3566, rk3568, rk3562, rv1103, rv1106, rv1103b, rv1106b, rk2118
model.export(format="rknn", name="rk3588")
新增Python程式檔之後,點擊VS Code工作列右下角,設定Python解譯器(參閱「OrangePi(香橙派)5 Max(二):從VS Code遠端SSH連線、開發Python程式」)。
執行Python轉換過程中,程式會先把.pt格式(PyTorch模型檔)轉換成通用的ONNX(Open Neural Network Exchange,開放式類神經網路交換)格式,然後再轉換成Rockchip處理器專屬的RKNN格式。

轉換完畢,它會顯示存檔的資料夾名稱與檔案大小:

該資料夾包含模型檔的配置描述文件和RKNN格式的模型檔。稍後還會用到yolo11n.pt檔來測試視訊物件偵測效能,yolo11n.onnx模型檔可以保留或刪除。

使用yolo11n.pt模型檔測試影片物件偵測的效能
底下是使用OpenCV讀取720p畫質的影片,透過預設的“yolo11n.pt”模型檔偵測影片中的物件,整個過程都在香橙派5 Max的CPU上運算,每秒僅能處理不到2個影格畫面(左下角顯示FPS: 1.78)。

OpenCV + YOLO影片物件偵測的完整Python程式碼如下:
import cv2 # 引用OpenCV套件
from ultralytics import YOLO # 引用YOLO套件
import time
def process_video(video_path, model_path, output_filename):
"""
使用YOLO物件偵測處理輸入影片,用邊界框包圍偵測物件、
顯示物件名稱和FPS,並儲存輸出影片。
參數:
video_path (str):輸入影片檔的路徑。
model_path (str):YOLO模型檔的路徑。
output_filename (str):處理完成的輸出影片檔名。
"""
try:
model = YOLO(model_path) # 載入YOLO模型檔
except Exception as e:
print(f"載入YOLO模型時出錯了:{e}")
return
cap = cv2.VideoCapture(video_path) # 開啟「輸入影片」
if not cap.isOpened(): # 檢查影片檔是否開啟成功
print(f"無法載入影片:{video_path}.")
return
# 獲取影片的解析度和FPS
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps_original = int(cap.get(cv2.CAP_PROP_FPS))
print(f"輸入影片的尺寸:{frame_width}x{frame_height}, FPS:{fps_original}")
# 設定輸出影片的編碼和格式
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 使用mp4v編碼
out = cv2.VideoWriter(output_filename, fourcc, fps_original, (frame_width, frame_height))
prev_frame_time = 0
new_frame_time = 0
while cap.isOpened(): # 若影片處於開啟狀態…
ret, frame = cap.read() # 持續讀取每個影格畫面
if not ret:
break
# 偵測畫面裡的物件
results = model(frame, stream=True)
# 處理每個偵測結果
for r in results:
# 取得偵測到的物件的邊界座標、置信度和分類名稱
boxes = r.boxes
names = r.names
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
confidence = float(box.conf[0])
class_id = int(box.cls[0])
label = names[class_id]
# 繪製邊界框
color = (0, 255, 0) # 綠色邊界框
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
# 標示分類和置信度
text = f"{label}: {confidence:.2f}"
cv2.putText(frame, text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 計算FPS
new_frame_time = time.time()
fps = 1 / (new_frame_time - prev_frame_time)
prev_frame_time = new_frame_time
# 在畫面左下方顯示FPS(取到小數點後兩位)
cv2.putText(frame, f"FPS: {fps:.2f}",
(10, frame_height - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(255, 255, 255), 2) # 白色文字
# 顯示處理後的畫面
cv2.imshow('Object Detection', frame)
# 儲存處理後的畫面到輸出影片
out.write(frame)
# 按 'q' 鍵退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 釋放資源
out.release()
cv2.destroyAllWindows() # 關閉視窗
print(f"物件偵測完畢的影片檔已存:{output_filename}")
if __name__ == "__main__":
input_video = 'example.mp4' # 指定輸入影片的名稱路徑
yolo_model = 'yolo11n.pt' # 指定YOLO模型檔的名稱路徑
output_video_name = 'yolo11n_ok.mp4' # 指定輸出影片檔名
# 偵測「輸入影片」裡的物件,並將結果存入「輸出影片」。
process_video(input_video, yolo_model, output_video_name)
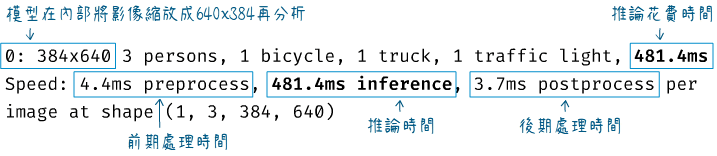
在程式執行階段,終端機會顯示每個影格的處理時間訊息,底下是其中一個訊息,推論(影像物件偵測)時間花費481.4毫秒(每個畫面的處理時間都不太一樣)。
在執行程式之前,可先在終端機輸入底下的命令,每秒更新一次NPU的使用狀況:
watch -n 1 sudo cat /sys/kernel/debug/rknpu/load
執行結果如下,它顯示在進行影像偵測的過程中,程式完全沒有利用到NPU。觀測完畢後,按Ctrl+C鍵可停止監測。

使用RKNN模型檔測試影片物件偵測的效能
底下是改用從yolo11n.pt轉換成RKNN格式的模型檔,進行視訊物件偵測的結果,得益於香橙派5 Max的RK3588內建的NPU的推理運算,每秒可以處理超過7個影格畫面:

上一節的程式碼只需修改一行,把yolo11n.pt檔改成RKNN模型檔所在的目錄路徑“./yolo11n_rknn_model”,路徑名稱前的“./”代表「當前目錄」。
if __name__ == "__main__":
input_video = 'example.mp4' # 指定輸入影片的名稱路徑
yolo_model = './yolo11n_rknn_model' # 指定RKNN模型檔的所在目錄
output_video_name = 'rknn_ok.mp4' # 指定輸出影片檔名
底下是程式執行階段,終端機會顯示的其中一個訊息,推論(影像物件偵測)時間花費79.0毫秒。

從觀測NPU的負載看來,這個RKNN模型檔並沒有完全發揮RK3588 NPU的性能,它僅用了其中一個核心進行推論,負載最高約35%。

「Rockchip RKNN 导出Ultralytics YOLO11 模型」貼文底下,官方開發人員有回應網友的問題,並且提到會持續優化此工具。
現階段,如果要在RK3588晶片上獲得更好的視覺推論效能,請採用舊版YOLO,像這個Yolov5_RK3588開源專案,效能好很多。