一個AI應用涉及三個層面:

有少數企業同時擁有整合AI應用上、下游的研發能力,例如:Google、Tesla(特斯拉)、華為、阿里巴巴…等,而本文介紹的Hailo AI加速晶片,屬於硬體層面。晶片研發公司Hailo本身並不開發語言模型,他們提供的AI程式,是基於Hailo AI加速器,在視覺辨識和文字生成等應用的Python和C++範例。
上一篇文章介紹了搭載Hailo-10H晶片與8GB記憶體的ASUS UGen300 USB AI加速器、安裝Windows驅動程式、LLM語言模型以及跟它對話的辦法,本文將說明如何透過Python程式跟Hailo AI加速器連線。
安裝HailoRT Python套件
安裝Windows驅動程式時,若有勾選“Python Package (pyHailoRT)”,它便會下載HailoRT(執行環境)的Python套件,預設儲存在這個路徑:C:\Program Files\HailoRT\python,如下圖所示:
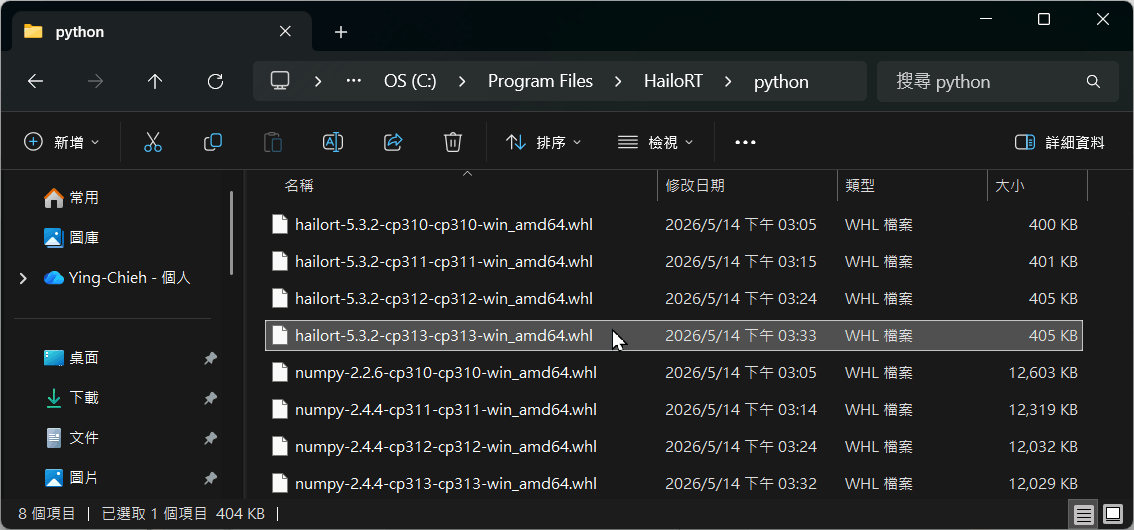
從套件的檔名cp310~cp313可看出,它支援Python 3.10 ~ 3.13版。我在D磁碟新增一個asus-hailo資料夾,然後執行底下命令,在裡面建立一個Python 3.13的虛擬環境。

接著啟動Python虛擬環境,在虛擬環境中輸入底下命令安裝Python 3.13版的HailoRT Python套件以及NumPy套件:
pip install "C:\Program Files\HailoRT\python\hailort-5.3.2-cp313-cp313-win_amd64.whl" pip install "C:\Program Files\HailoRT\python\numpy-2.4.4-cp313-cp313-win_amd64.whl"
連接Hailo環境的大語言模型
Hailo公司在這個Github網頁(hailo-apps),提供一些Python範例程式,包括文字對話、辨識圖片內容、語音轉文字和語音助理。
我已事先下載擅長程式設計的語言模型 “qwen2.5-coder:1.5b”,所以在Chrome瀏覽器的Page Assist模組,嘗試用這個模型生成本文的測試程式。
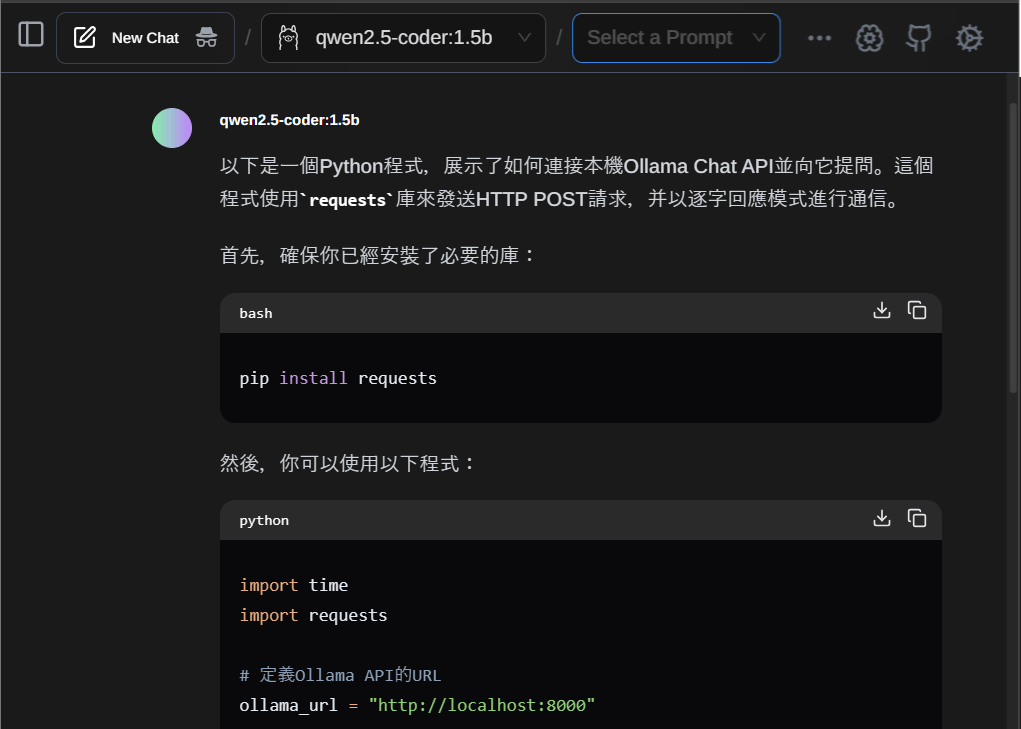
這是我提交給本地模型的提示詞:
請寫一個連接本機Ollama Chat API,向它提問並顯示答覆的Python程式,需求: - 本機ollama的位址:"localhost:8000" - 語言模型名稱:"qwen2:1.5b" - 提問內容:"請推薦5個觀賞極光的北歐城市" - 開啟串流(stream)模式,逐字回應。 - 最後顯示這個程式花費的處理時間
這是模型生成的程式碼:
import time
import requests
# 定義Ollama API的URL
ollama_url = "http://localhost:8000"
# 定義模型名稱
model_name = " qwen2:1.5b "
# 定義提示內容
question = "請推薦5個觀賞極光的北歐城市"
# 构建POST请求的数据
data = {
"prompt": question,
"temperature": 0.7,
"max_length": 2048,
"stream_response": True
}
# 初始化一個空字典來存儲逐字回應
responses = []
# 使用逐字回應模式進行通信
start_time = time.time()
response = ""
for byte in iter(lambda: requests.post(ollama_url, json=data).iter_content(), b''):
if byte == b'\n':
response += byte.decode('utf-8')
responses.append(response)
response = ""
start_time = time.time() # 更新起始時間
else:
response += byte.decode('utf-8')
end_time = time.time()
processing_time = end_time - start_time
print("答案:")
print("\n".join(responses))
print(f"處理時間:{processing_time:.6f} 秒")
你可以看到一個明顯的錯誤:POST請求的data數據集裡面沒有定義model(採用的模型名稱)。我們可以繼續在這個瀏覽器介面跟它交談,請它修正程式。底下是我自己修改後的版本:
import requests
import json
import time
# 定義Ollama API的URL和模型名稱
url = "http://localhost:8000/api/chat"
model_name = "qwen2:1.5b"
# 定義提示內容
question = "請推薦5個觀賞極光的北歐城市"
data = {
"model": model_name,
"temperature": 0.7,
"max_length": 2048,
"messages": [
{"role": "user", "content": question}
]
}
print(f"問題:{question}\n")
start_time = time.time()
print("思考中,請稍候…\n")
try:
res = requests.post(url, json=data, stream=True)
if res.status_code == 200:
answer_started = False
responses = ""
for line in res.iter_lines():
if not line:
continue
data = json.loads(line.decode("utf-8"))
content = data.get("message", {}).get("content", "")
if content and not answer_started:
print("開始回答\n")
answer_started = True
if content:
print(content, end="", flush=True)
responses += content
if data.get("done"):
elapsed = time.time() - start_time
print(f"\n\n處理時間:{elapsed:.2f}秒")
break
else:
print(f"\n出錯了! ({res.status_code}): {res.text}\n")
except Exception as e:
print(f"\n連線失敗: {e}\n")
執行程式之前,請先在終端機執行 “hailo-ollama” 啟動HailoRT執行環境,並且要事先下載指定的語言模型(參閱上一篇文章)。若指定的模型不存在,將顯示如下訊息:
出錯了! (404): {"error":"model 'gemma4:2b' not found"}
底下是”qwen2:1.5b”模型的回覆,花費時間70.68秒。
問題:請推薦5個觀賞極光的北歐城市 思考中,請稍候… 開始回答 以下是一些著名的北歐城市,其中一些地方常被認為是觀賞極光的理想之地: 1. 斯德哥爾摩(瑞典):斯德哥爾摩以其迷人的夜空中空和多變的天象而聞名。在冬季,天空中常常可以看到明亮的极光。 2. 奥林匹亞斯agenti(挪威):奧林匹亞斯是北歐最著名的極光觀察地點之一,每年春天到秋季都有大量的觀賞活動。 3. 瑪麗雅(冰島):冰島因其火山活動引起的熱量和地形特征而著稱,這使它成為了全球知名的極光觀察地點。冰島的夜晚經常可以看到強烈的極光。 4. �******/京(芬兰):在芬蘭的瓦萨市,你可以找到一個著名的滑雪場,在那里你可以欣賞到非常亮的極光。 5. 克羅地亞的布拉迪斯瓦夫(克羅地亞):在克羅地亞的布拉迪斯瓦夫,有一個著名的極光观测站,該地區每當有極光時都會變得非常亮。 請注意,這些地方的極光可能不是全年都明亮的,因此最好是在特定季節或特定時間去看。 處理時間:70.68秒
Hailo-10H執行大型語言模型的效能表現
根據我之前「換新筆電以及測試13台電腦執行本機大型語言模型(LLM)的效能」這篇貼文的測試結果,Hailo AI加速器在LLM的表現,並不理想。
Hailo公司的Model Explorer Generative AI(生成式AI模型)瀏覽頁,列舉了所有預先編譯模型的資料,以 “qwen2-1-5b” 模型為例,該網頁揭示的數據:
- 首次載入時間(First Load Time In Sec):3.66秒
- 首個詞元生成時間(Time To First Token In Sec):0.32秒
- 每秒生成的詞元數(TPS):8.06
這是因為機器學習有不同的架構,Hailo AI加速器適合處理CNN(卷積神經網路)架構的影像識別任務:當晶片將模型檔(靜態權重)讀入記憶體後,就可以高速掃描圖像元素,反覆推理出辨識結果。
而基於Transformer架構的大語言模型,每次生成一個詞元(token),就要把整個模型的權重全部輪詢一遍,才能生成下一個詞元,屬於記憶體頻寬密集型運算。雖然 Hailo-10H晶片支援Transformer,讓它能在低功耗的前提下跑得動LLM,實現本機隱私與離線部署,但它的設計初衷是「省電與可行性」,而非「極致的生成速度」。
在模型推理期間,Hailo AI加速器的耗電量僅2.0~2.3W(底下照片中的電流計顯示2.1W),外殼的溫度約34.5°C。不進行推理時,消耗電流僅約0.1A~0.2A。
