本文使用的「ASUS UGen300 USB AI加速器」由華碩電腦AI加速器產品經理Matt提供,特此感謝。
華碩電腦最近推出AI加速器產品,可分擔本地終端設備(如:個人電腦、工業電腦、單板微電腦或智慧型手機)繁重的AI推理運算,離線進行文字生成、語音轉文字稿、影像辨識、物體偵測…等任務,讓設備能順暢地同時處理其他工作。
在某些人類難以到達或進入的區域,像是高山、荒野或深海,或者網路環境會因地理位置而受到限制或者干擾的地區,如:長隧道、戰地前線、災後地區,又或者涉及隱私的區域,像是掃地機器人的AI攝影機,這些智慧型設備需要即時、自主判斷能力,而非仰賴雲端伺服器做決策。
AI推理的性能越高往往越耗電,而華碩AI加速器採用Hailo-10H NPU(類神經網路處理器),可提供高達40 TOPS (INT4) 的推理效能,且內建8GB LPDDR4記憶體,在一般工作負載下功耗僅約2.5W。
這款產品有USB和M.2兩種介面型式,支援Linux, Windows及Android系統的x86與ARM架構。產品名稱、外觀以及華碩官方的商品介紹網頁的連結如下:

ASUS UGen300 M2 AI模組,另有搭載2GB RAM的版本。

筆者曾在去年5月介紹過另一款Hailo-8產品(參閱:賦予樹莓派AI超能力),它們都採用Hailo Technologies公司設計的晶片。Hailo公司總部位於特拉維夫(Tel Aviv),根據EE Times(電子工程專輯)的“Secretive Israeli AI accelerator Hailo reveals key details of its news AI Edge Accelerator”報導,Hailo於2017年2月由以色列國防軍精英情報單位(也就是Unit 8200)的退役成員創立,已成功從一家初創公司發展為人工智慧領域名副其實的明星。
根據維基百科的Hailo Technologies條目,經過幾輪的募資,Hailo公司的估值曾高達12億美元,是標準的AI晶片獨角獸,主要投資者包括瑞士著名的工業與自動化巨頭ABB、日本NEC、豐田集團旗下的大發汽車還有以色列最大的汽車進口與代理龍頭Delek Automotive Systems。以色列財經媒體《CTech》於2026年4月3日發表的這篇新聞指出,Hailo正籌劃在華爾街進行首次公開發行(IPO)。
目前Hailo公司推出三款AI晶片,Hailo-8, Hailo-10H和Hailo-15,提供合作廠商生產AI加速器模組和AI視覺辨識產品。底下是Hailo-8和Hailo-10H模組的比較:
|
Hailo-8模組 |
Hailo-10H模組 |
|
|---|---|---|
|
NPU核心 |
第一代Dataflow架構 | 第二代Dataflow架構 |
|
峰值算力(TOPS) |
26 TOPS (INT8) | 40 TOPS (INT4) / 20 TOPS (INT8) |
|
專用記憶體 |
無 | 搭載LPDDR4 8GB RAM |
| 典型功耗 | 約2.5瓦 | 約2.5瓦 |
| 介面型式 | M.2 (Key A/E/M) | M.2 或 USB 3.1 Gen 2 Type-C |
| 主流模型支援 | 電腦視覺(CNN, YOLO) | 視覺 + 生成式 AI(LLM, VLM, Whisper) |
Dataflow(資料流)是Hailo的專利技術,該公司的Technology(技術)頁面有動畫說明:它把神經網路模型的每一層結構,映射成晶片內部微小運算單元的連線。資料就像工廠的生產線一樣,從第一個單元流入、沿路計算,最後吐出答案,效率高且省電。
而傳統的CPU和GPU晶片在處理AI運算時,需要反覆「從記憶體讀取資料→計算→存回記憶體」,因此比較耗電且會發熱,不利於應用在供電受限、體積小的邊緣裝置(如:無人機、監控攝影機、車載電腦、機器狗)。
先強調一點:請勿將AI加速器產品跟雲端AI服務比較。坦白說,AI加速器在智慧層面上根本無法與任何雲端服務匹敵,但AI加速器是優先考慮在離線、本地運作、保護隱私、低延遲和低功耗使用場合的利器。
Hailo-15不是AI加速晶片而是系統晶片(SoC),它本身內建4核心的 ARM CPU(Cortex-A53)、影像訊號處理器(ISP)、影片編碼器(H.264/H.265),以及20 TOPS (INT8) 峰值算力的NPU(用於視覺,不具備LLM能力),用於擔任IP Camera(網路攝影機)的主控晶片,自己就能接攝影機、解碼影像、進行AI視覺辨識且傳送串流視訊。
ASUS UGen300 USB AI加速器開箱
這是ASUS UGen300 USB AI加速器的包裝和內容物,包裝盒清楚標示「用於生成式AI和視覺AI的低功耗加速器」以及支援的系統架構。

內容物還包含一條USB 3.1 Type-C短線(長約21公分,傳輸線兩端都是Type-C接頭)以及一小冊多國語文簡介和保固,操作說明書請自行在AI加速器的產品服務網頁下載。
此AI加速器的本體約重146g,這是它和第一代任天堂Switch遊戲機的尺寸對比。

從外殼的厚度看來,我以為它的電路板是一個USB加M.2插槽,外加一個M.2 Hailo-10H 模組。外殼很好拆,只有四顆螺絲。我想多了,它就是一塊整合USB介面的電路板,加上厚實的鋁散熱片,電路板的面積跟M.2 2280規格的SSD相同。

拆掉鋁合金外殼,電路板加上散熱片的重量約84g。晶片和散熱片之間使用導熱膠固定,重複黏貼會嚴重影響導熱效果,所以我就沒有繼續拆了。

外殼內部有兩塊強力磁鐵,能讓本體牢牢吸附在金屬外殼的電腦上,但我的筆電外殼材質是塑膠和鎂鋁合金…我試過將它吸附在冰箱上,很牢靠。可惜,我家的冰箱不是執行Linux/Windows/Android系統,也沒有USB 3.1介面,不支援AI加速應用。
安裝UGen300 USB AI加速器的Windows驅動程式
連接此AI加速器的設備,至少需具備2GB RAM,建議4GB。單純就硬體要求而言,許多NAS網路儲存裝置,甚至Wi-Fi分享器,例如,華碩的ROG Rapture GT-BE19000AI都符合條件,所以理論上,AI加速器可用在這些長時間運作的設備。
UGen300 AI加速器的官方說明文件,目前只有Linux的安裝操作說明;本文以執行Windows 11系統的筆電示範。
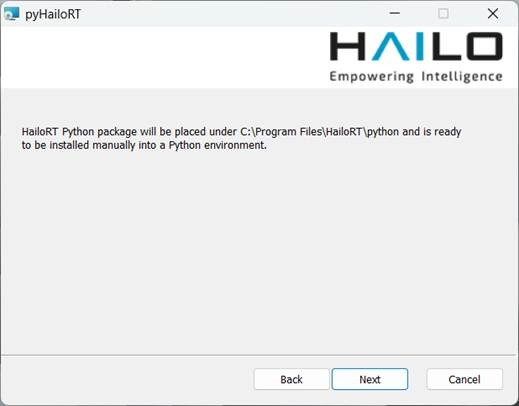
請先到AI加速器的產品服務網頁下載Windows驅動程式。安裝過程,除了PCIe驅動程式不用裝(用於M.2介面的產品),其餘都建議安裝,日後開發Python程式時會用到。
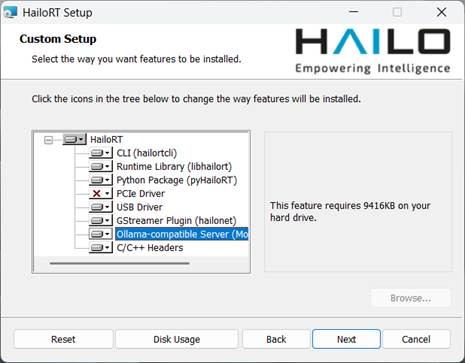
安裝之前,它會提示這些程式的儲存路徑:
更新UGen300 USB AI加速器的韌體
上文的程式安裝畫面當中,第一個程式 “CLI (hailortcli)” 是個文字命令版的HailoRT(RT代表Run Time,執行環境),相當於Hailo AI加速器硬體和應用程式(如:Python)之間的橋樑。
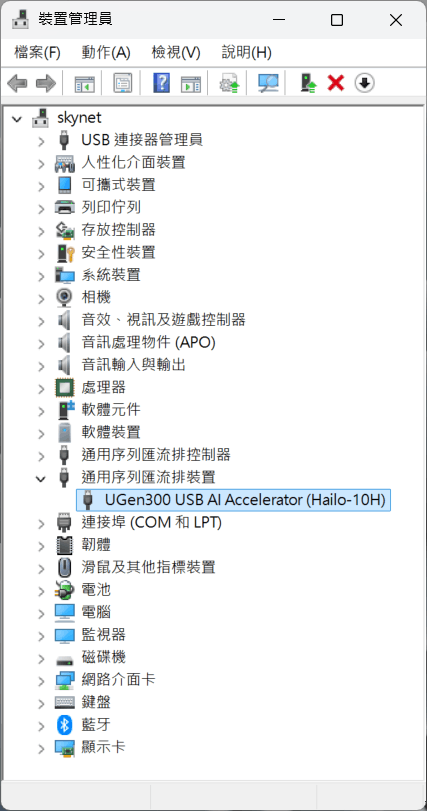
把UGen300 USB AI加速器接上電腦,可以在「裝置管理員」看到它:
開啟Window命令提示字元,輸入“hailortcli fw-control identity” 命令,可查看AI加速器的韌體版本資訊:
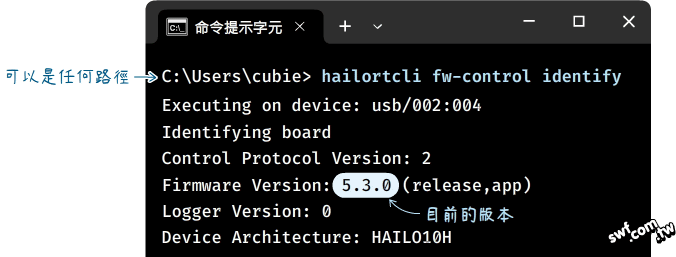
或者,直接從Windows的「開始」,找到並執行剛才安裝的 “Hailo USB FW Update”(韌體升級)工具:
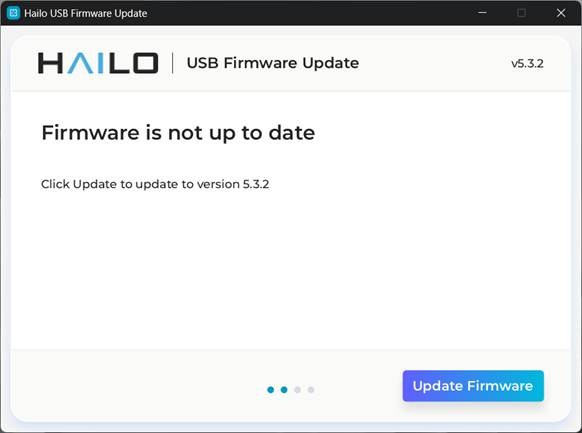
點擊Start(開始),它會檢測AI加速器的韌體版本。下圖顯示「韌體不是最新版」,點擊Update Firmware即可更新。
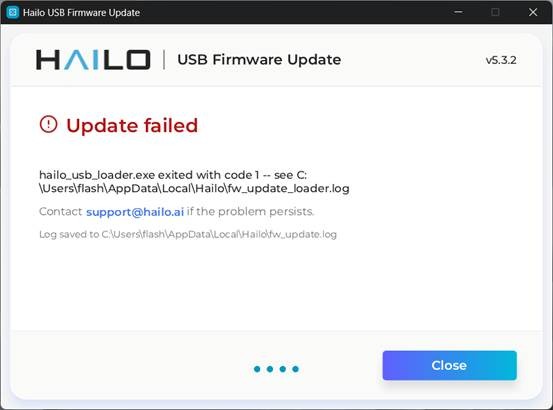
更新韌體過程不要關閉此視窗,也不要拔除AI加速器。過了一會兒…額…它提示更新失敗。
在命令提示字元執行之前的hailortcli命令,結果顯示韌體已更新到最新版。
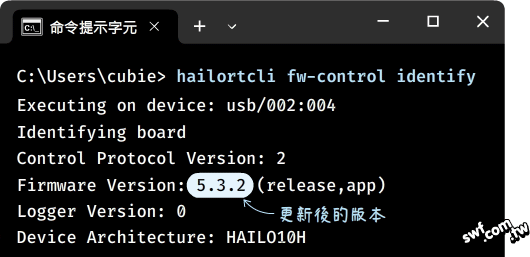
再次執行 “Hailo USB FW Update”(韌體升級)工具,這次它也顯示韌體是最新版,所以上面的錯誤可能是檢測軟體的小bug。
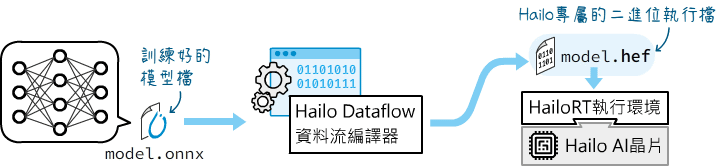
Hailo專屬的.hef模型檔
Hailo Model Zoo GenAI(Hailo模型庫)開源專案有提供針對Hailo的AI處理器優化(編譯)的LLM(Large Language Model,大型語言模型)檔、模型編譯工具,以及“hailo-ollama”應用程式(基於HailoRT執行環境的C++編寫的Ollama相容API)。
Ollama是能讓使用者在本機電腦執行LLM的軟體,可自由安裝各種語言模型,不必仰賴雲端AI服務,相關說明請參閱《透過Ollama在本機電腦執行大型語言模型》貼文,以及《超圖解Python程式設計》。
上文安裝的Windows驅動程式過程,已一併安裝hailo-ollama。
「Ollama相容API」代表現有連接Ollama或者為Ollama編寫的程式,經少許修改,即可轉接到Hailo,在AI加速器上運作。Hailo模型庫Models(模型)頁面,列舉了Hailo公司挑選的一些模型(原始檔以及預先編譯檔),例如:
- Qwen3-1.7B-Instruct:用於文本對話與輕量級邏輯推理的大型語言模型檔。Instruct代表經過指令微調(Instruction-tuned),適合日常對話、文字創作或角色扮演。1.7B代表17億個參數,檔案小、速度快,非常適合部署在資源有限的邊緣裝置。
- Qwen3-VL-2B-Instruct:VL代表Vision-Language(視覺語言),不只能讀文字,還能看懂圖片與影片。這一類模型統稱VLM(視覺語言模型)或多模態模型。
- Qwen2.5-Coder-1.5B-Instruct:具備程式碼生成、除錯與補全能力的程式碼專用模型。
- Whisper-Small:用於語音辨識(語音轉文字)與語音翻譯的模型,能把聲音檔當中的語音轉換成精準的文字(包含標點符號)。
我們可以透過「Hailo模型庫」專案頁面提供的Dataflow編譯器,自行把其他格式(如:.onnx)的模型檔編譯成.hef格式。本文將直接下載與使用預先編譯好的模型。
啟動hailo-ollama以及列舉預編譯的語言模型檔
hailo-ollama本身沒有內建大語言模型,需要額外下載。請先在Windows命令提示字元輸入“hailo-ollama”命令啟動它,若執行順利,它會提示我們已運行在本機電腦的8000埠。
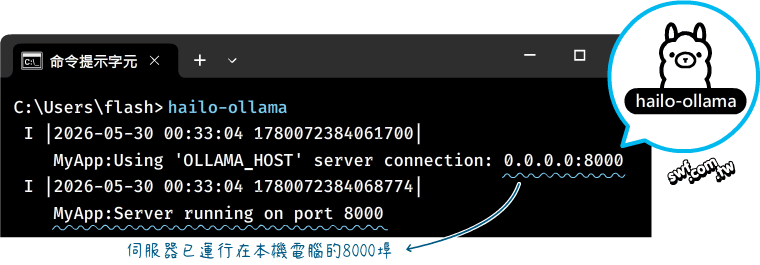
在hailo-ollama運作過程,請不要關閉上面的命令提示字元;關閉該視窗,hailo-ollama將停止運作。
接著就可以透過HTTP連線請求來操作hailo-ollama。例如,發出下圖左的HTTP請求,hailo-ollama將以JSON資料格式,傳回所有可用的語言模型檔名。HTTP請求的“localhost”網域,可改寫成“127.0.0.1”或者本機電腦的IP位址。
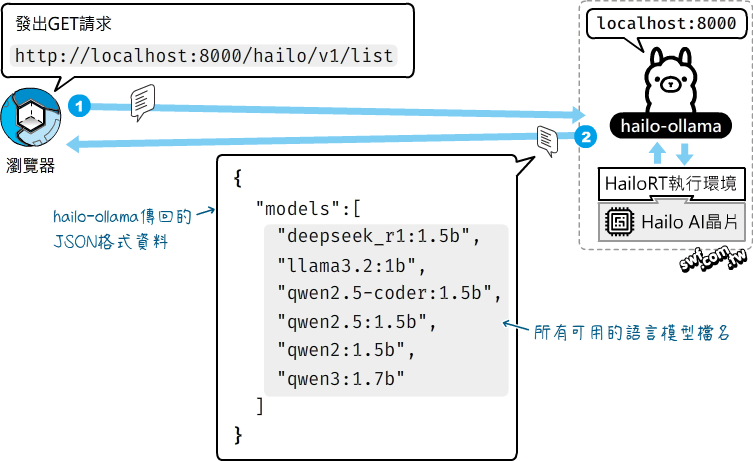
在瀏覽器輸入以上的HTTP請求網址的結果:
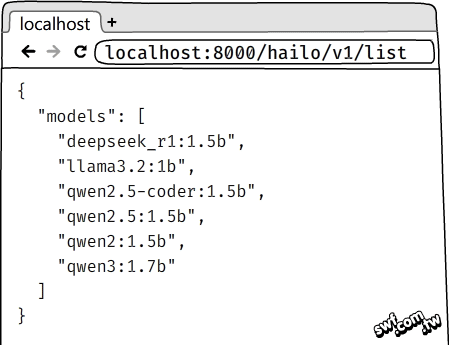
Hailo模型庫開源專案網頁,則是用curl命令示範。curl代表Client(用戶端)URL,是個在終端機(命令提示字元)執行的工具程式,用於向伺服器發送網路請求(HTTP Request)以及傳輸資料。
開啟另一個命令提示字元視窗,輸入底下的命令,也能取得可用的模型檔名:

使用curl命令下載預編譯的語言模型檔
假設要在本機安裝 “qwen2:1.5b” 模型,我們需要向本機伺服器的 “http://localhost:8000/api/pull” 網址,發出內容類型(Content-Type)為JSON,資料內容為 ‘{ "model": "qwen2:1.5b", "stream" : true }’ 的HTTP請求。
把這個要求寫成curl命令,將是這樣:
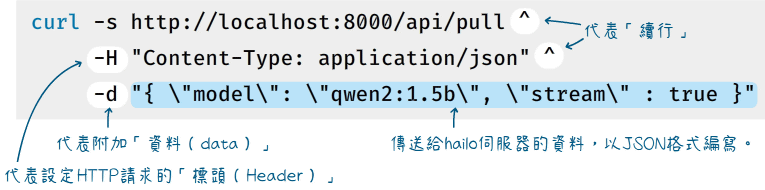
在命令提示字元執行這個命令:
curl -s http://localhost:8000/api/pull ^
-H "Content-Type: application/json" ^
-d "{ \"model\": \"qwen2:1.5b\", \"stream\" : true }"
伺服器將自動連線到Hailo模型庫下載指定的"qwen2:1.5b"模型檔。在Windows系統上,本機模型檔將存放在這個路徑:
%USERPROFILE%\AppData\Local\hailo-ollama\models\blob
我下載了兩個語言模型:
透過AI加速器跟本機語言模型對話
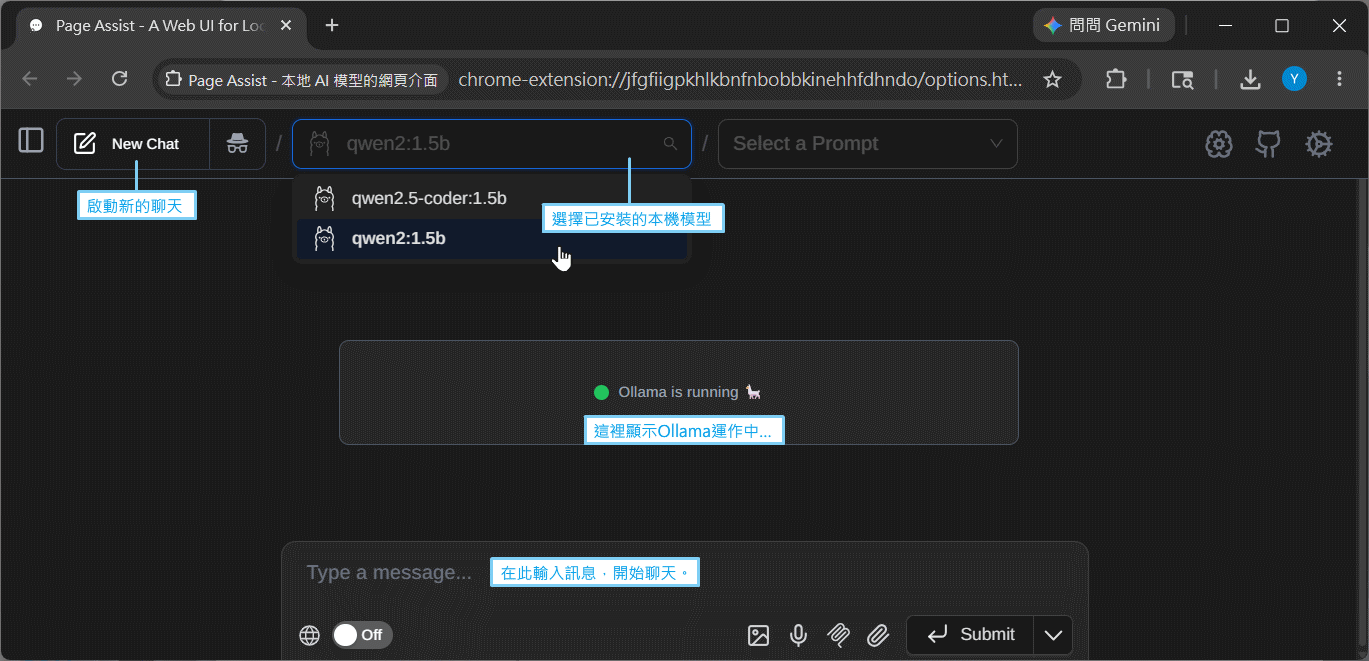
跟本機大語言模型對話,最簡單的方式之一,是透過Chrome瀏覽器的Page Assist擴充功能模組,請先在Chrome瀏覽器安裝它:
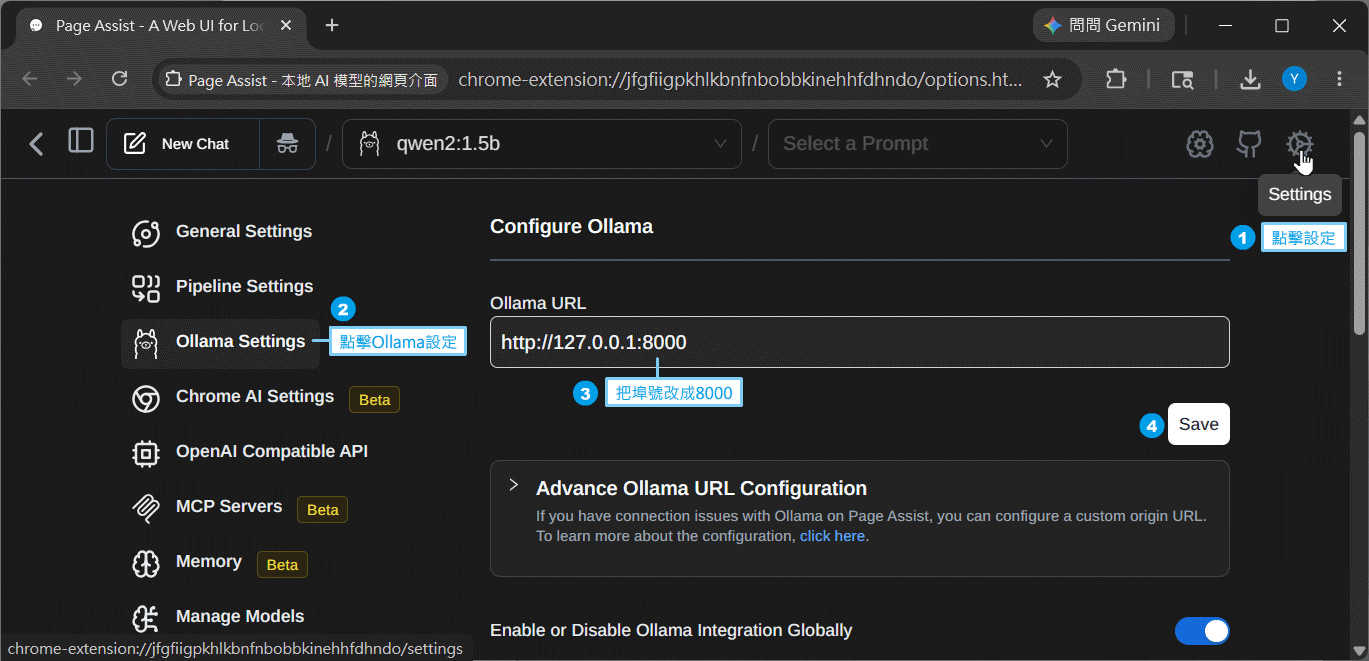
啟動Page Assist,按照下圖的步驟,點擊Settings(設定),修改Ollama伺服器的埠號:
儲存之後,即可看到「Ollama運作中」的訊息,可以開始跟你選擇的語言模型聊天了。