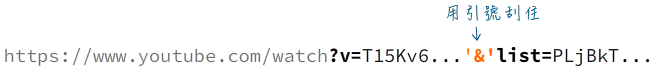下載YouTube影片的Pytube程式庫有個下載播放清單影片的Playlist類別,本文將修改之前的YouTube影音下載程式碼,讓它下載播放清單中的全部影片。
取得YouTube播放清單網址
以Great Art Explained頻道為例,點擊其中一個播放清單:
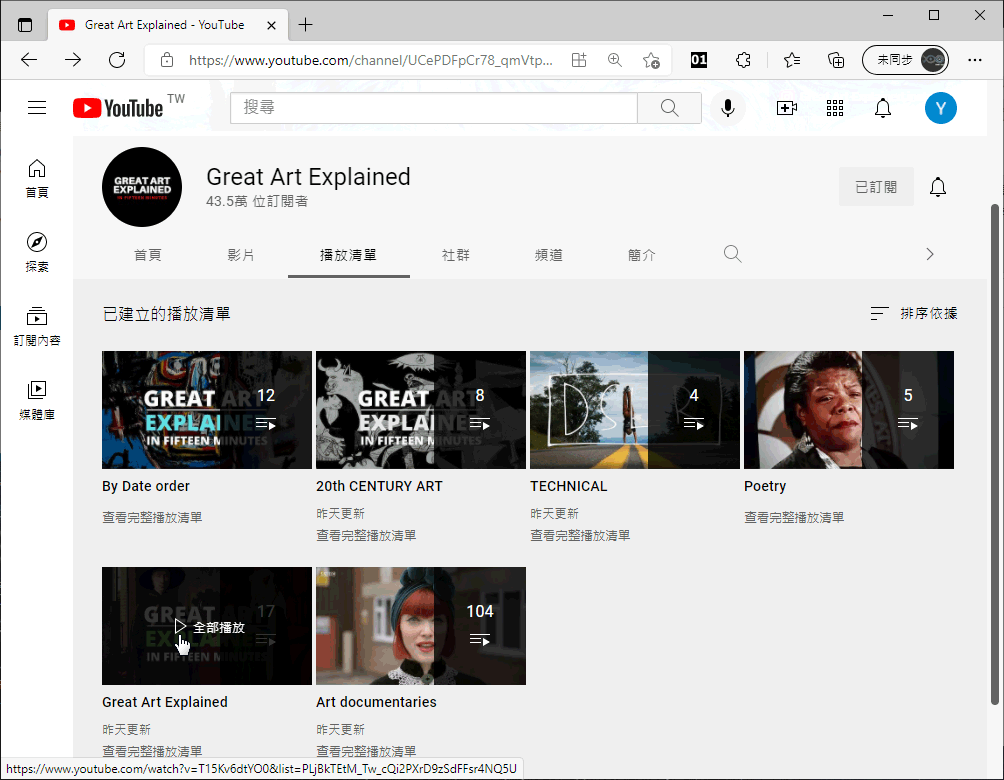
瀏覽器將透過這個網址播放影片:
https://www.youtube.com/watch?v=T15Kv6dtYO0&list=PLjBkTEtM_Tw_cQi2PXrD9zSdFFsr4NQ5U
如果點擊右側播放清單裡的任一影片,上面的網址後面會加上一個代表索引編號的index參數。
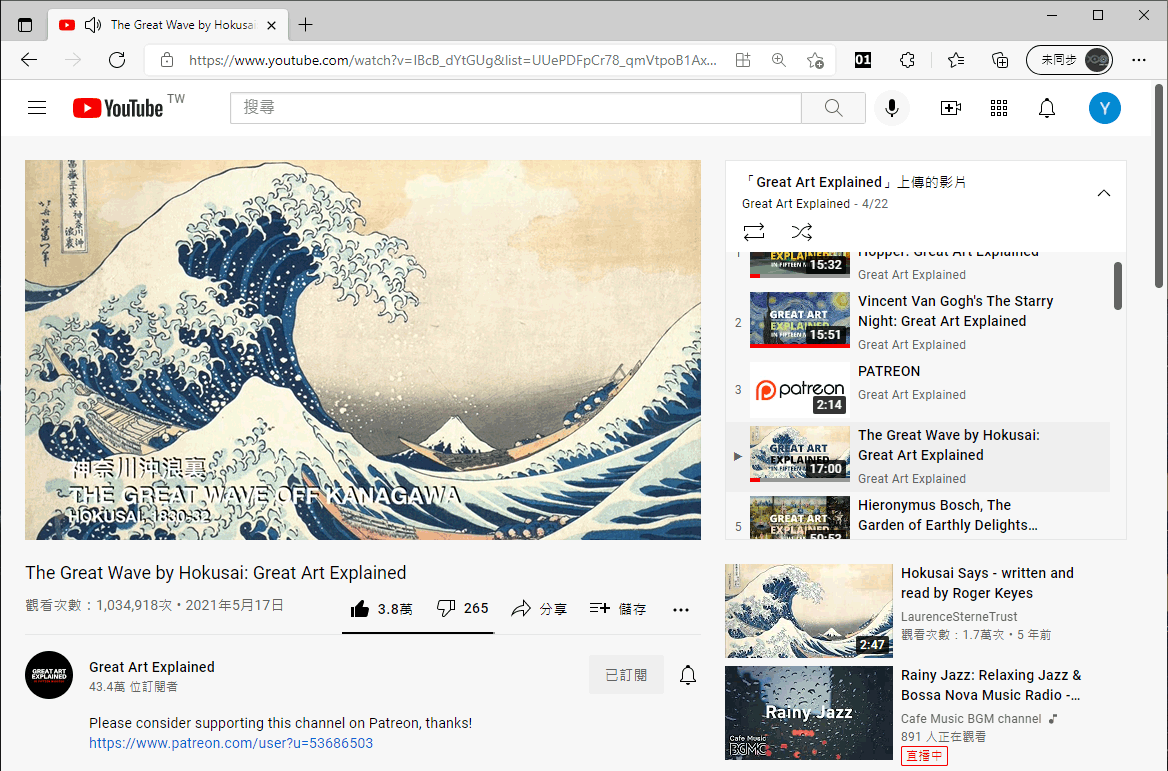
所以,播放清單影片的網址格式如下,透過程式下載影片時,index參數可以省略,因為無論是否添加index參數,都能取得清單裡的所有影片的網址。
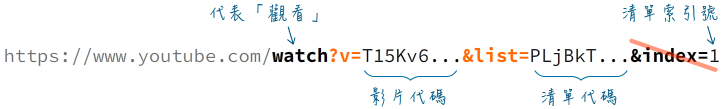
透過YouTube伺服器的playlist程式,也能取得指定的播放清單的影片,格式如下:

例如,把上面網址裡的list參數,剪貼到playlist網址後面,將能檢視清單中的所有影片:
https://www.youtube.com/playlist?list=PLjBkTEtM_Tw_cQi2PXrD9zSdFFsr4NQ5U
透過Pytube的Playlist類別取得「播放清單」的所有影片網址
Pytube程式庫的Playlist類別接收一個「播放清單」網址;底下敘述將建立一個名叫‘pl’的Playlist物件,透過pl物件的video_urls屬性,或直接存取pl物件,都能傳回列表(list)格式的影片網址清單。
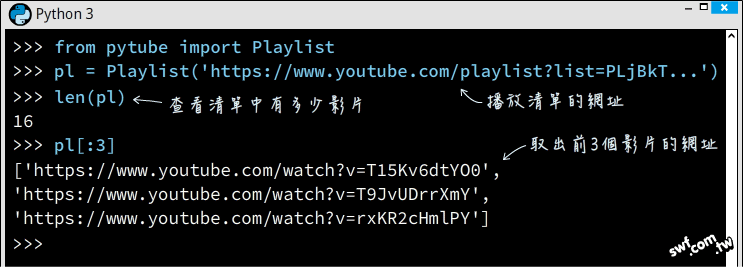
Playlist類別物件(即pl物件)包含YouTube物件,因此底下敘述可下載播放清單的全部影片:
for video in p.videos: video.streams.first().download()
本文的程式僅利用Playlist取得影片清單的全部網址,執行下載和合併影音的程式,沿用之前的程式碼。
筆者將下載播放清單影片的Python程式檔命名成tube_list.py,它支援之前的所有命令行參數,如:-a(僅下載聲音)和-fhd(高畫質格式),並新增一個指定下載影片數量的-end參數。
例如,在終端機或命令提示字元中執行tube_list.py,它將下載指定播放清單當中的前三個高畫質影片:
python tube_list.py 播放清單網址 -fhd -end 3
tube_list.py程式檔修改自之前的tube.py檔,main()函式的改動內容如下:

check_urls()函式負責從播放清單中取出一個網址,交給download_media()函式進行下載:
def check_urls():
global args
global file_index # 下載檔的列表索引
global download_count
download_count = 1
if file_index < len(videos):
vars(args)['url'] = videos[file_index] # 把影片網址傳給url參數
file_index = file_index + 1
print("下載影片:", vars(args)['url'])
download_media(args)
download_media()函式將從args物件取得包含url(影片下載網址)在內的參數,所以上面的程式把下載影片的網址寫入args物件的url參數,這部份的相關說明請參閱「YouTube影片下載(一):合併視訊和音軌的Python程式」。
下載播放清單影片的完整Python程式碼
tube_list.py的完整程式碼如下:
# -*- coding: utf-8 -*-
import argparse
import os
import platform
from pytube import YouTube
from pytube import Playlist
import subprocess
args = {}
fileobj = {}
download_count = 1
file_index = 0
def pyTube_folder():
sys = platform.system()
home = os.path.expanduser('~')
if sys == 'Windows':
folder = os.path.join(home, 'Videos', 'PyTube')
elif sys == 'Darwin':
folder = os.path.join(home, 'Movies', 'PyTube')
if not os.path.isdir(folder): # 若'PyTube'資料夾不存在…
os.mkdir(folder) # 則新增資料夾
return folder
def onProgress(stream, chunk, remains):
total = stream.filesize
percent = (total-remains) / total * 100
print('下載中… {:05.2f}%'.format(percent), end='\r')
def video_res(yt):
res_set = set()
video_list = yt.streams.filter(type="video")
for v in video_list:
res_set.add(v.resolution)
# 傳回解析度表列,例如:['720p', '480p', '360p', '240p', '144p']
return sorted(res_set, reverse=True, key=lambda s: int(s[:-1]))
def download_media(args):
try:
yt = YouTube(args.url, on_progress_callback=onProgress,
on_complete_callback=onComplete)
except:
print('下載影片時發生錯誤,請確認網路連線和YouTube網址無誤。')
return
filter = yt.streams.filter
if args.a: # 只下載聲音
target = filter(type="audio").first()
elif args.fhd:
target = filter(type="video", resolution="1080p").first()
elif args.hd:
target = filter(type="video", resolution="720p").first()
elif args.sd:
target = filter(type="video", resolution="480p").first()
else:
target = filter(type="video").first()
if target is None:
print('沒有您指定的解析度,可用的解析度如下:')
res_list = video_res(yt)
for i, res in enumerate(res_list):
print('{}) {}'.format(i+1, res))
val = input('請選擇(預設{}):'.format(res_list[0]))
try:
res = res_list[int(val)-1]
except:
res = res_list[0]
print('您選擇的是 {} 。'.format(res))
target = filter(type="video", resolution=res).first()
# 開始下載
target.download(output_path=pyTube_folder())
def check_media(filename):
out = subprocess.run(["ffprobe", filename],
stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
if (out.stdout.decode('utf-8').rfind('Audio') == -1):
return -1 # 沒有聲音
else:
return 1
def merge_media():
vars(args)['a'] = False # 清空a參數
temp_video = os.path.join(fileobj['dir'], 'temp_video.mp4')
temp_audio = os.path.join(fileobj['dir'], 'temp_audio.mp4')
temp_output = os.path.join(fileobj['dir'], 'output.mp4')
cmd = f'ffmpeg -i {temp_video} -i {temp_audio} \
-map 0:v -map 1:a -c copy -y {temp_output}'
try:
subprocess.run(cmd, shell=True)
# 視訊檔重新命名
os.rename(temp_output, os.path.join(fileobj['dir'], fileobj['name']))
os.remove(temp_audio)
os.remove(temp_video)
print('視訊和聲音合併完成')
check_urls()
except:
print('視訊和聲音合併失敗')
def onComplete(stream, file_path):
global download_count, fileobj
fileobj['name'] = os.path.basename(file_path)
fileobj['dir'] = os.path.dirname(file_path)
print('\r')
if download_count == 1:
if check_media(file_path) == -1:
print('此影片沒有聲音')
download_count += 1
try:
# 視訊檔重新命名
os.rename(file_path, os.path.join(
fileobj['dir'], 'temp_video.mp4'))
except:
print('視訊檔重新命名失敗')
return
print('準備下載聲音檔')
vars(args)['a'] = True # 設定成a參數
download_media(args) # 下載聲音
else:
print('此影片有聲音,下載完畢!')
check_urls()
else:
try:
# 聲音檔重新命名
os.rename(file_path, os.path.join(
fileobj['dir'], 'temp_audio.mp4'))
except:
print("聲音檔重新命名失敗")
# 合併聲音檔
merge_media()
def check_urls():
global args
global file_index
global download_count
download_count = 1
if file_index < len(videos):
vars(args)['url'] = videos[file_index] # 設定成url參數
file_index = file_index + 1
print("下載影片:", vars(args)['url'])
download_media(args)
def main():
global videos
global args
parser = argparse.ArgumentParser()
parser.add_argument("url", help="指定YouTube視訊網址")
parser.add_argument("-sd", action="store_true", help="選擇普通(480P)畫質")
parser.add_argument("-hd", action="store_true", help="選擇HD(720P)畫質")
parser.add_argument("-fhd", action="store_true", help="選擇Full HD(1080P)畫質")
parser.add_argument("-a", action="store_true", help="僅下載聲音")
parser.add_argument("-end", action="store", help="影音清單數量上限")
args = parser.parse_args()
try:
pl = Playlist(args.url)
if args.end:
videos = pl.video_urls[:int(args.end)]
else:
videos = pl.video_urls
except:
print('下載影片時發生錯誤,請確認網路連線和YouTube網址無誤。')
return
# print('影片列表: ', videos)
check_urls()
if __name__ == '__main__':
main()
執行這個程式檔時要留意,Windows的CLI介面,如PowerShell,不允許命令參數包含'&'字元;若YouTube影片網址包含'&'字元,執行時將會出現如下的錯誤訊息:
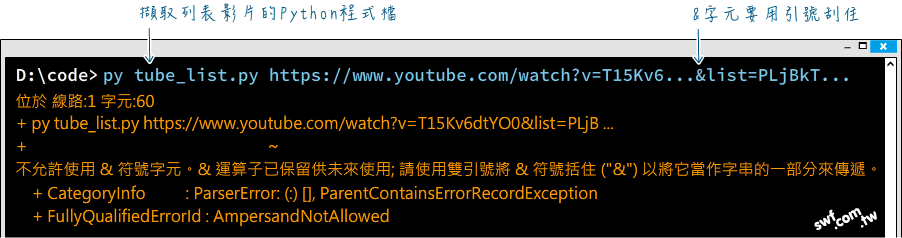
請把'&'字元用引號刮住,或改用上文提到的playlist網址就可以了: