
作者:趙英傑
出版社:旗標科技股份有限公司
出版日期:2019.7.4
頁數:576頁
定價:NT$650
- 超圖解程式語法、人人都能看得懂
- 實用專案邊做邊學、擺脫枯燥語法
- 豐富多元應用、動手實作時數個專案
- YouTube影片自動下載、商品詢價網路爬蟲、Google試算表自動化、Flask網站建置、資料庫與留言板、LINE聊天機器人、圖檔浮水印產生器、自動縮圖產生器、人臉偵測器、人臉辨識、家電控制、刷臉門禁系統…
Python是Guido van Rossum(吉多‧范羅蘇姆)在90年代初期設計出的程式語言,如今是最常用的程式設計語言之一,舉凡Amazon、YouTube、Google、Yahoo!、NASA等大型企業和組織也青睞採用Python開發各種工具。Python的語法簡潔易讀,是少數既適合程式初學入門,且廣泛用於大數據處理∕深度學習等高階科學計算應用,也能在拇指大小的微電腦控制板運作的全領域、通用型程式語言。
本書以圖解、實作為出發點,除第一章的程式語言基礎、文字命令操作、安裝Python與程式編輯環境,每個章節都有實例與詳細圖解,帶領讀者學習Python程式設計。
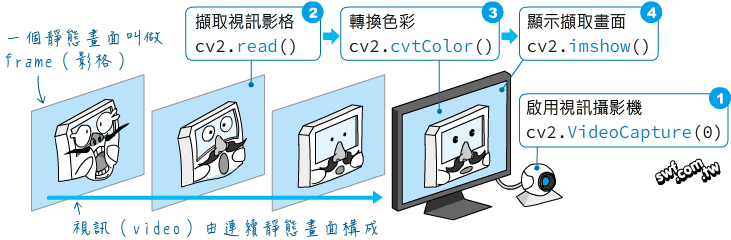
在許多實作應用的場合,光是了解程式語法是不夠的,像建構網路應用程式,還需要具備網路、防火牆、資料庫系統、租用並在雲端空間佈署應用程式…等概念,本書也針對這些基礎做了全方位的說明。
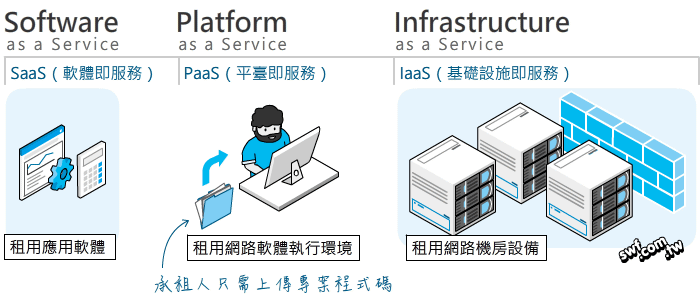
某些Python入門書籍沒有觸及的部分,例如:物件導向程式設計,因為很重要,所以筆者也用幾個淺顯實用的案例圖解說明。
《超圖解Python程式設計入門》章節大綱
第1章 認識Python程式語言
第2章 變數與條件判斷程式
- 規劃與製作問答題測驗程式
- 改變程式流程的if條件式
- 處理字串資料
- 格式化字串
第3章 列表、迴圈與自訂函式
- 儲存多筆相關資料的列表(list)
- 使用迴圈執行重複作業
- 使用 for…in 讀取序列結構資料
- 建立自訂函式

第4章 操作資料夾與文件:同步備份檔案
- 使用os程式庫操作檔案
- 使用argparse套件處理命令參數
- 嘿 Python~現在幾點?
- 直接執行 Python 程式檔
- 「可變」與「不可變」的資料類型和 Tuple(元組)
第5章 建立命令行工具:下載YouTube影片
- YouTube影音的Codec與下載視訊
- 將影片存入系統的預設路徑:辨別系統平台
- 使用 set(集合)建立不重複的選項列表
- 資料排序
- 使用try…except捕捉例外狀況
- 使用 FFmpeg 轉換多媒體檔案格式
第6章 自動收集網路資訊
- 認識網頁與HTML
- 認識瀏覽器操控工具:Selenium
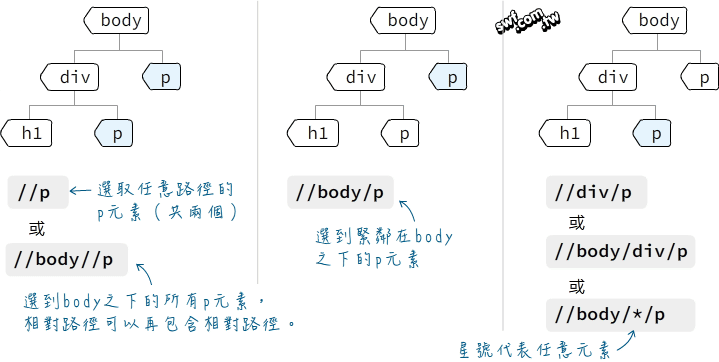
- 使用XPath語法選定HTML元素
- 認識查詢字串
第7章 儲存檔案:純文字檔、CSV檔與Google試算表
- 使用字典(dict)儲存結構化資料
- 在本機電腦儲存資料
- 讀寫CSV檔
- 使用Google雲端試算表儲存資料
第8章 建立自訂類別
- 自訂類別:遠離義大利麵條
- 儲存試算表資料的自訂類別
- 網路應用程式訊息交換格式:XML與JSON
- 儲存Python原生資料:pickle

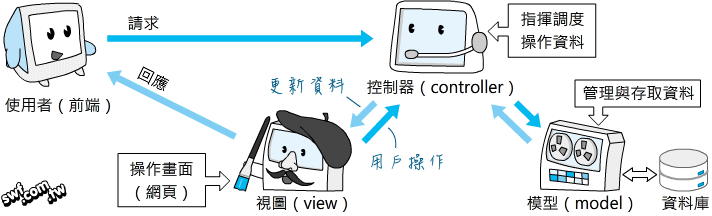
第9章 使用Flask建置網站服務
- 認識HTTP通訊協定
- Flask網站應用程式設計
- 存取靜態網頁檔
- 認識樣板與樣板引擎
- 處理表單
第10章 佈署網站到雲端空間
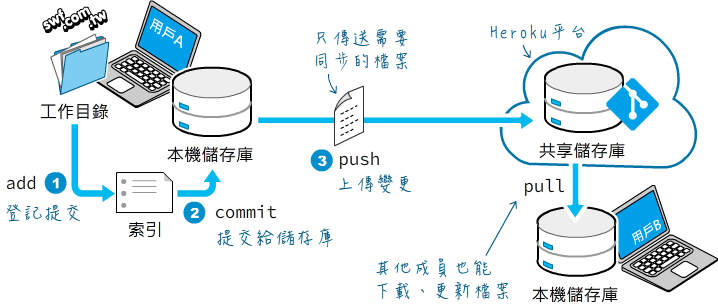
- 建立虛擬環境
- 佈署Flask網站程式到雲端平台
- 認識程式原始檔版本管理工具與Git
- 安裝與初設 Git 前端工具
- 設置Heroku CLI與發布檔案
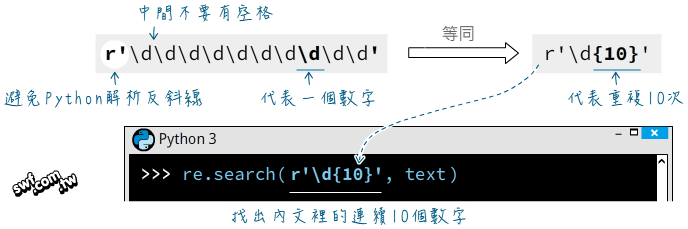
第11章 多執行緒下載檔案、規則表達式以及定時執行工作排程
- 透過Python程式發出HTTP請求
- 藉由MIME類型篩選檔案格式
- 規則表達式
- 下載JavaScript產生的動態內容
- 多執行緒同時下載多個檔案
- 定時執行程式碼
第12章 留言板網站應用程式
- 規劃資料表結構
- 產生SQLite資料庫檔案與操作資料
- 新增留言的表單網頁
- 認識 Cookie 和 Session
- 管理員登入

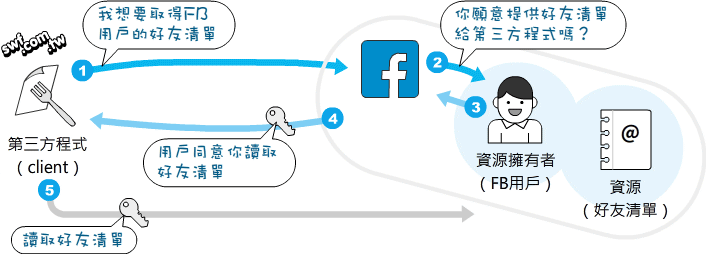
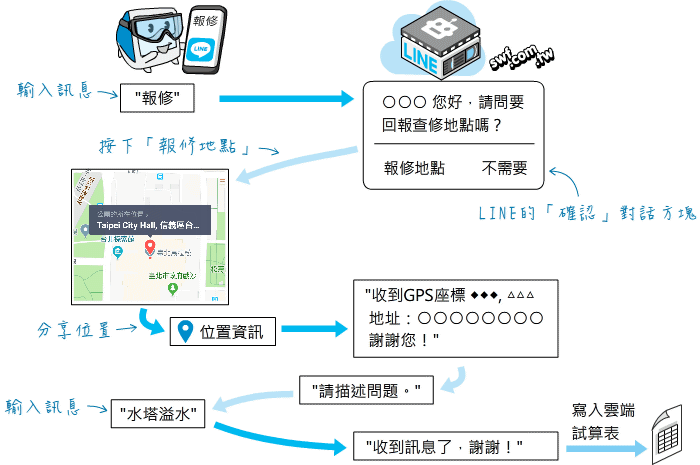
第13章 打造 LINE 聊天機器人
- LINE bot 聊天機器人程式開發
- LINE 線上報修
- 建立 LINE 圖文選單
第14章 影像處理與人臉辨識
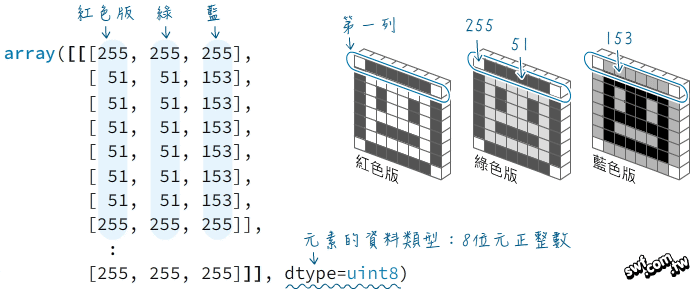
- NumPy 與影像處理
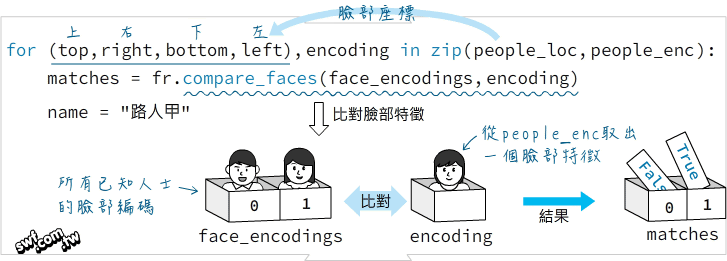
- 人臉識別程式
- OpenCV 即時人臉辨識
附錄A 列表生成式、裝飾器、產生器和遞迴
- 列表生成式 (list comprehension)
- 裝飾器語法說明
- 用產生器(generator)處理巨量資料
- 用遞迴改寫費式數列函式

附錄B LINE Bot物聯網:控制家電開關
- 從 MicroPython 控制板發送 LINE 訊息
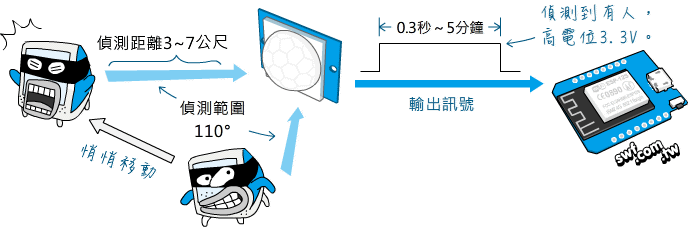
- PIR人體感應器
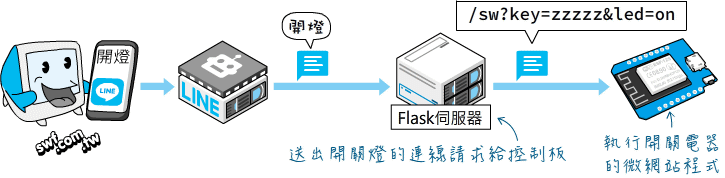
- 從 LINE 開關燈
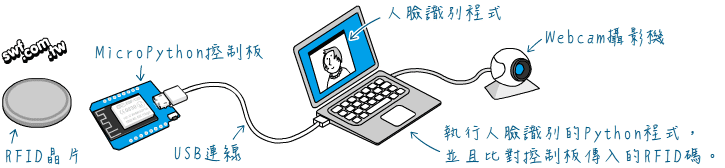
附錄C 人臉識別+RFID 門禁系統實驗
又有新作品出現了~~~
要趕快來去入手才行~~~
不過還要等到7/4號… >.<
Python目前真的還蠻好用的~~~
各個領域幾乎都看得到它~~~
裝個anaconda就能邊寫邊測試~~~
預祝新書大賣~~~
謝謝Kevin!
thanks,
jeffrey
今天很興奮的要去訂書~~~
結果博客來出版日期是7/5 … 要明天才能下訂了….
拍謝~其實7/1已經印好、入庫,只是物流作業需要一點時間,我也尚未收到書。
thanks,
jeffrey
博客來速度還蠻快的, 7/5下訂, 今天(7/7)收到囉~~~
又要認真的來當個讀書人了~~~
非常感謝Kevin的支持!
thanks,
jeffrey
請問會上架到 amazon 繁體中文嗎?
行銷通路由出版社統籌負責,旗標似乎沒有這個打算。
thanks, jeffrey
趙英傑老师您好,打开网页的一瞬间,心跳加速,终于又看到新书了:)
预祝新书大卖———-
咦?也许我该尝试写官能小说…,谢谢 🙂
thanks,
jeffrey
介紹說明寫得清楚易懂,書更亦如是,祝 趙哥每本新書都大賣!
Bing
謝謝Bing, 轉眼又過了一年多了~
thanks,
jeffrey
老師您好:
請問書4-16頁中,其中
src=path.join(args.src,’ ‘)
dest=path.joint(args.dest,’ ‘)
是否應該改成
src=path.join(args.src,’\’)
dest=path.joint(args.dest,’\’)
上面的註解說路徑後面需要加分隔字元,是加上’ \’ 還是’\’呢?
不是喔,請參閱4-4頁說明。
另外,建議可以先在Python直譯器直接輸入import os和os.path.join(‘路徑’, ”)之類的敘述測試語法。
thanks,
jeffrey
你好,
在進行本書P2-17實作:
X 加[續行符號]
X 使用[小括號]
一直無法在直譯器中執行成功,實在不清楚發生什麼原因,盼能解惑。
PS:有截圖記錄,但此處無法上傳圖片。
請開啟範例檔ch02資料夾裡的code.txt,直接把多行字串貼入命令行視窗試試。
thanks,
jeffrey
老師您好:
請問C-11頁裡的程式碼和下載的serial_com.py裡的內容不一樣,書裡的有附在檔案裡嗎?
拍謝,C-11頁的程式碼如下,感謝告知!
import serial from webcam import Face dataset_file = 'D:\\dataset\\staff.dat' user_id = 0 # 序列埠相關程式 COM_PORT = 'COM3' # 請自行修改序列埠名稱 BAUD_RATES = 230400 ser = serial.Serial(COM_PORT, BAUD_RATES) def get_RFID(id): global user_id user_id = id print('使用者的RFID:', id) # 點亮控制板的綠燈 ser.write(b'PASS\n') if ser.in_waiting: RFID_str = ser.readline().decode() # 接收回應訊息並解碼 tag_id = int(RFID_str, base=16) print('掃描到的RFID:', tag_id) if tag_id == user_id: ser.write(b'OPEN\n') # 開門 print('門打開了!') else: print('卡片比對錯誤!') ser.flushInput() # 清除序列埠輸入值 face = Face(dataset_file, get_RFID) face.start()thanks,
jeffrey
老師您好:
請問5-31批次轉換媒體檔案的src(來源路徑),那個src是要在c:\music\音訊的,”music”之前設製一個src資匣嗎?例如:C:\src\music\音訊
這裡有點看不懂
另外我想請教,我覺得您解釋的很詳細,當下我在實作也都ok,但發現做完要再回頭想說自己寫又寫不出來,這方面是否可指點一下要如何學習比較能融匯貫通?
謝謝老師
做出來了,不過我把opencv轉交給”樹莓派”處理,因為這個門禁裝置想實際裝在大門用,用筆電太大XD.
對了,書裡提到如果要改接12v的電控鎖,要插上miniD1的繼電器,那繼電器是否可支援12或24v的直流電呢?
多練習、多閱讀;分析程式和電路的時候,我都會用到筆,釐清輸入和輸出的關係。
繼電器也是用電磁驅動的開關,接微電腦的繼電器電磁鐵的驅動電壓是5V,另一側是受磁鐵吸引的開關,通常都可以接120V以上。
thanks,
jeffrey
你好:
在第五章,用了 pip 安裝 pytube 後
在編譯器打上 from pytube import YouTuBe,它顯示 Unable to import ‘pytube’pylint(import-error)
請問老師這個要怎麼解決?
“YouTube”的b要小寫。
thanks,
jeffrey
你好:6-26頁的取讀【我是神隱少女】文字,顯示錯誤如下
>>> driver.get(‘http://swf.com.tw/’)
>>> p = driver.find_element_by_xpath(‘//p[@class=”hidden”]’)
Traceback (most recent call last):
File “”, line 1, in
p = driver.find_element_by_xpath(‘//p[@class=”hidden”]’)
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py”, line 394, in find_element_by_xpath
return self.find_element(by=By.XPATH, value=xpath)
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py”, line 978, in find_element
‘value’: value})[‘value’]
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py”, line 321, in execute
self.error_handler.check_response(response)
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/errorhandler.py”, line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {“method”:”xpath”,”selector”:”//p[@class=”hidden”]”}
(Session info: chrome=78.0.3904.108)
假設hidden.html位於D磁碟的ch06資料夾,它的URL路徑為:
url = ‘file:///D:/ch06/hidden.html’
測試執行這個敘述沒有問題:
p = driver.find_element_by_xpath(‘//p[@class=”hidden”]’)
thanks,
jeffrey
我以為這篇是可以看到老師提供的網址上的隱藏文章內容,看來是我誤解,這篇是指自己設定的網站嗎?
1. 那個範例單純只是說明如何擷取隱藏的內容。
2. 如果指定的網頁元素不存在,它就會傳回像你遇到的錯誤訊息;為了避免錯誤,可以用try…catch包圍find_element_by_xpath那一行敘述。
thanks,
jeffrey
老師您好:
我正依照第六章一步步學習,做到章節最後的整合部份,依範例yahoo.py,我嚐試抓取蝦皮的商品名稱出現以下錯誤,不知是否是轉換問題或網頁節點定位上有問題呢?(最下方附上程式碼)
商品名稱: [, , , , , , , , , , , , , , ]
商品數量: 15
————————————————————————————————————————-
# -*- coding: utf-8 -*-
from selenium import webdriver
from urllib import parse
search_key=parse.quote(‘ESP8266′)
url=’https://shopee.tw/search?kw={key}&p={key}&sort=-ptime’
url=url.format(key=search_key)
option=webdriver.ChromeOptions()
option.add_argument(‘headless’)
d_path=r’C:\webdriver\chromedriver.exe’
d=webdriver.Chrome(d_path,options=option)
d.implicitly_wait(10)
d.get(url)
title_s=’//div[contains(@class,”col-xs-2-4 shopee-search-item-result__item”)]/div/a/div/div[2]/div[1]/div’
title=d.find_elements_by_xpath(title_s)
print(‘商品名稱:’,title)
print(‘商品數量:’,len(title))
每個電子商務網站的搜尋「查詢字串」定義都不一樣,使用Python測試之前,可以先在瀏覽器輸入yahoo購物網站查詢字串格式,你將發現蝦皮購物網站無法傳回你指定的搜尋內容。
蝦皮購物的查詢字串請參閱第七章mybid.py檔,main()函式裡的sites列表,第3個元素就是蝦皮的相關定義。
thanks,
jeffrey
老師您好:
我一步步照著做7-3的mybid_csv,run的時候什麼都沒有出現,包含應該要出現的新的CSV檔也沒有。
顯示畫面如下:================== RESTART: /Users/joyce 1/Documents/jmybid.py =================
>>>
請問這部分是怎麼了呢?
這之中的建立簡單的csv檔和寫內容進去都有成功(範例ch7_1~ch7_5)
1. 請開新的終端機視窗再執行mybid_csv.py測試看看。
2. 根據程式第8行的定義,新增的CSV檔將存入D磁碟。
thanks,
jeffrey
老師您好:我重新在檢查一次,發現有些地方自己打錯,現在程式是有反應,但顯示錯誤如下:
================== RESTART: /Users/joyce 1/Documents/jmybid.py =================
Traceback (most recent call last):
File “/Users/joyce 1/Documents/jmybid.py”, line 97, in
main()
File “/Users/joyce 1/Documents/jmybid.py”, line 89, in main
titles, prices, links = open_page(driver, url, title_path, price_path, link_path)
File “/Users/joyce 1/Documents/jmybid.py”, line 21, in open_page
links = driver.find_elements_by-xpath(link_path) #擷取連結
AttributeError: ‘WebDriver’ object has no attribute ‘find_elements_by’
>>>
這部分反覆重做後,現在yahoo和露天的都會紀錄在csv裡,但跑到蝦皮的就會直接跳到關chrome,然後這部分就不在csv檔裡看到,也沒有顯示任何錯誤訊息
再麻煩比對你的程式碼與書本範例程式檔。
thanks,
jeffrey
links = driver.find_elements_by_xpath(link_path) 這一行的最後一個底線,你打成減號了。
thanks,
jeffrey
打成減號我有發現並修改,現在又變這樣,顯示如下:
Traceback (most recent call last):
File “/Users/joyce 1/Documents/jmybid.py”, line 97, in
main()
File “/Users/joyce 1/Documents/jmybid.py”, line 79, in main
driver = webdriver.Chrome(driver_path)
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/chrome/webdriver.py”, line 73, in __init__
self.service.start()
File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/common/service.py”, line 104, in start
raise WebDriverException(“Can not connect to the Service %s” % self.path)
selenium.common.exceptions.WebDriverException: Message: Can not connect to the Service /Users/joyce 1/webdriver/chromedriver
>>>
請檢查webdriver的路徑是否正確,ChromeDriver是否存在指定的路徑。
thanks,
jeffrey
這部分的路徑沒有改過,之前可以用,只修改蝦皮這部分的網址之後,就顯示如此訊息
webdriver這部分好像壞掉了,剛試6-14最簡單的部分也是出現一樣的錯誤,請問老師,這樣該如何解決?
請重新下載WebDriver覆蓋之前的chromedriver.exe
thanks,
jeffrey
老師,您好!我是香港的讀者。我前陣子買了老師的”超圖解Python程式設計入門” 一書。但在實踐過程中,遇到了一些困難。
我完成第12 章的練習,想把 留言板網站放上去”Heroku ”寄存,可是我已經試了3、4天,有上網查過其他人怎樣做,但還是不行。
我有用第1 0章的練習去試是成功的。所以想請教老師: 像第12 章的資料庫要如何上載到”Heroku ”寄存,讓整個留言板網站可以順利運行。
*
我這幾天一直疑到的是application error。
我今天才試到會出現server error 字眼。
謝謝
我下週三之前會更新一篇文章說明在heroku寄存第12章留言板的流程。
thanks,
jeffrey
老師,您好!很開心終於成功了! 我把sqlite 資料庫換成postgresql。今天試了一整天,一直出現500 的錯誤提示,原來是要在Heroku 上create_all() 。
我也更新相關文章了:佈署Python Flask網站留言板應用程式到Heroku + PostgreSQL資料庫系統
thanks,
jeffrey
老師,辛苦你了
不客氣~
thanks,
jeffrey
你好,我又回來了,開始繼續學習,
以下回報一下。
pip 19.3.1後,已經不能直接打pip,要加上python -m。
因為目前作到7-27發現”被”更新了。
“python -m pip install”和”pip install”的差別在於,”python -m”會區分當前的Python版本(2.x或3.x),進而下載安裝對應的模組。
虛擬環境只有一個Python版本,所以執行”python -m pip install”或”pip install”,並沒有差別。
thanks,
jeffrey
老師您好:
在flask章節中,我執行9_1.py出現以下訊息,請教這是什麼狀況?
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xa9 in position 0: invalid start byte
那個錯誤訊息代表你的Python程式檔不是用UTF-8格式儲存,在VS Code編輯器中修改編碼的方式,請參閱2-4頁。
thanks,
jeffrey
老師早:
我去vs code照書裡的重新設定成utf8(原本就已設定了),也試了spyder和sublime,執行後還是不行,我在想是不是win10系統本身的語言,後來試著去win10系統設定裡的有一個的選項打勾後重開機,就ok了
感謝告知!不過,Windows 10的編碼就是Unicode,請問你之前沒有勾選哪個選項?
thanks,
jeffrey
記得昨天有打上在哪設定,但留言後沒看到….
在控制台>時鐘與區域>地區>系統管理>變更系統管理>beta:使用unicode UTF-8提供全球語言支援(這裡打勾)
謝謝,看到了…但我的Win10系統那個選項並沒有打勾,也沒有出現過UTF-8錯誤。
thanks,
jeffrey
哈哈~~,老師您出的書一路跟著做下來,講解很詳細,大致有個概念,雖然還不會自行獨立寫出一套自己想寫的程式,至少在市面上看的到的運用,有了些許的概念。謝謝您。
非常感謝!
thanks,
jeffrey
老師你好
請問5-14頁
自訂函數 onProgress裡面
不太了解 stream 和remaining
這兩個參數我要帶什麼東西進去耶??
stream是不是要帶入 yt.stream
那remaining??他也是個函數嗎??自己就會計算尚待下載的位元組大小??
onProgress是YouTube()的回呼函式(5-13頁),它會在下載影片過程中自動被呼叫並且接收來自YouTube物件傳入的參數;
自訂函式只負責處理接收到的參數值,例如,從YouTube傳入的stream(串流物件)得知影片檔大小、從remaining參數取得剩餘的下載位元組數量,這樣就能計算出已下載的百分比值了。
thanks,
jeffrey
老師您好
超圖解Python程式設計入門一書14章的程式已經執行過了 沒有大問題 使用staff.dat的程式也ok
唯獨若使用create_data.py重新產生新的staff.dat,(即使是用原附的照片及staff.csv檔也一樣)則其他程式都失效
檢查下载的staff.csv檔與書中14-33頁說明並不一致
不知是何原因
這是staff.csv檔的內容,你下載的跟這個不一樣嗎?
我剛剛測試create_data.py重新產生新的staff.dat,並沒有問題:
請問你有變更原始碼開頭的dataset和pict的路徑設定嗎?
為了確認不是新舊版本的問題,我重新編譯了dlib(19.19.0版)和face_recognition(1.2.3版),再執行一次create_data.py也沒問題。
thanks,
jeffrey
老師您好
網路下載的staff.dat檔案大小是3KB 重新編譯後是1KB
我用的是python3.68 dlib19.8.1 face_recognition(1.2.3版)opencv4.12.30 numpy1.17.54
把staff(D:\dataset)和pict資料夾放在d下執行create_data.py產生的staff.dat會使的face_rec.py辨識的人全變成路人甲 webcam_test.py只有人像而不辨識
若是變更原始碼開頭的dataset和pict的路徑設定如下
pict_path = ‘D:\\code\\ch14\\pict\\’ # 請自行修改路徑
csv_file = ‘D:\\code\\ch14\\dataset\\staff.csv’ # 請自行修改路徑
pickle_file = ‘D:\\code\\ch14\\dataset\\staff.dat’ # 請自行修改路徑
而create_data.py在d:\code\ch14中 dataset和pict的路徑也在d:\code\ch14中
則結果一樣 會使的face_rec.py辨識的人全變成路人甲 webcam_test.py只有人像而不辨識
換回原來3KB的staff.dat檔案 則又可以辨識了 還是不解
哦~真是抱歉吶~14-33頁的圖說是正確的,範例程式的staff.csv少了欄位標題,所以create_data.py程式(14-34頁上方的程式片段)抓不到資料。補上標題欄位的staff.csv內容:
thanks,
jeffrey
老師 您好
關於 staff.csv的問題 換台電腦 就正常了
謝謝
非常感謝糾錯!
thanks,
jeffrey
老師,您好:
這本書的9-23頁有一行程式碼:
@app.route(‘/about/’)
def about(user):
return render_template(‘index.html’,name=user)
這裡的做任何說明,name似乎沒有定義
另外about是一個頁面嗎?
這個程式我一直跑不出來,希望您能將這個程式碼
寫得更完整,細節能講得清楚些,最好是解說完能將程式碼
完整的列出 來
這種片段式的寫法對我們初學者很容易產生疑惑
最後感謝您的答覆
一位讀者 敬上
9-23頁的name,如該頁的程式圖說所示,是網頁樣板裡的變數名稱;about則是視圖函式名稱,它不是頁面,而是負責處理來自“/about”資源請求的函式;請參閱9-5和9-6頁說明。
請執行範例檔9-7,然後連結到本機網站的/about/路徑,後面加上一個名字,例如“阿蝙”,“阿蝙”這個字串將會被傳入about視圖函式,再傳達給HTML樣板。
第九章的所有Flask網站伺服器程式範例,都是從9-6頁的第一個範例延續、衍生下來。寫程式之前,我們習慣上會把問題拆解成不同的小單元或者功能,逐一完成、然後再組合這些「片段」。很多程式碼也不是從第一行重頭開始建立,像網頁、網站應用程式,都半都是運用已完成核心功能的「框架」,把框架提供的導覽列、互動選單、表單格式、資料驗證…等等,修改、組合成我們要的樣子。
不同Flask網站程式碼的架構其實大同小異,例如,這是範例檔9-5的程式碼(9-16頁的讀取靜態頁面單元):
from flask import Flask app = Flask(__name__) @app.route('/index.html') @app.route('/') def index(): return app.send_static_file('index.html') if __name__ == '__main__': app.run('0.0.0.0', 80, debug=True)比較一下範例檔9-7(9-23頁的動態網頁單元):
from flask import Flask, render_template app = Flask(__name__) @app.route('/index.html') @app.route('/') def index(): return app.send_static_file('index.html') @app.route('/about/')
def about(user):
return render_template('index.html', name=user)
if __name__ == '__main__':
app.run('0.0.0.0', 80, debug=True)
兩個Python程式的差別在於後者新增了3行“/about”路由程式,第一行新增引用render_template,其餘10行完全一樣。就我的觀看來看,當我閱讀到程式設計書籍裡面有多個重複、相同的程式碼,我會覺得有點囉唆,因為同樣的概念前面已經講過了。
不過,列舉整個程式碼再標註行號數字說明,對作者比較省事,或許也能增加頁數 🙂 我以後會盡量把每個範例檔內容完整印出來或者調整解說的方式。在此之前,煩請搭配書本的範例檔練習,非常謝謝Kevin的建議。
thanks,
jeffrey
老師你好:
我依超圖解Python程式設計入門第6-10頁,安裝selenium程式庫發生以下錯誤
D:\python> pip install selenium
Traceback (most recent call last):
File “c:\program files\python38\lib\runpy.py”, line 192, in _run_module_as_main
return _run_code(code, main_globals, None,
File “c:\program files\python38\lib\runpy.py”, line 85, in _run_code
exec(code, run_globals)
File “C:\Program Files\Python38\Scripts\pip.exe\__main__.py”, line 9, in
TypeError: ‘module’ object is not callable
請問如何解決,謝謝
錯誤訊息最後一行:TypeError: ‘module’ object is not callable
代表Python沒有加入系統環境變數(參閱1-7頁的安裝選項),
請確認這兩個路徑有加入Path環境變數:
“C:\Program Files\Python38\Scripts”
“C:\Program Files\Python38\”
然後再執行pip命令,應該就能成功安裝selenium了。
thanks,
jeffrey
老師你好:
我在第五章安裝Pytube時,執行Pip命令皆無問題
但依超圖解Python程式設計入門第6-10頁,安裝selenium程式庫發生錯誤
D:\python> pip install selenium
Traceback (most recent call last):
File “c:\program files\python38\lib\runpy.py”, line 192, in _run_module_as_main
return _run_code(code, main_globals, None,
File “c:\program files\python38\lib\runpy.py”, line 85, in _run_code
exec(code, run_globals)
File “C:\Program Files\Python38\Scripts\pip.exe\__main__.py”, line 9, in
TypeError: ‘module’ object is not callable
經查詢Path環境變數:含有
“C:\Program Files\Python38\Scripts”
“C:\Program Files\Python38\”
嘗試將Python3.8移除,再安裝Python3.7.3版後有成功執行pip命令
但再將3.7.3版移除後安裝3.8版後就依然產生上述錯誤
麻煩老師,謝謝
我剛剛把Python升級到3.8.1版,執行pip安裝selenium沒問題。
請試試用這個命令安裝:
python -m pip install selenium
或加上–user解決安裝權限不足的問題:
python -m pip install selenium –user
thanks,
jeffrey
老師你好,
課本P5-8頁,關於YouTube的pytube程式庫應用,一直出現如下的錯誤訊息:
Traceback (most recent call last):
File “d:/python/test.py”, line 3, in
yt = YouTube(‘https://www.youtube.com/watch?v=M7mMlOpRy6o’)
File “C:\Python37\lib\site-packages\pytube\__main__.py”, line 88, in __init__
self.prefetch_init()
File “C:\Python37\lib\site-packages\pytube\__main__.py”, line 97, in prefetch_init
self.init()
File “C:\Python37\lib\site-packages\pytube\__main__.py”, line 130, in init
mixins.apply_descrambler(self.player_config_args, fmt)
File “C:\Python37\lib\site-packages\pytube\mixins.py”, line 95, in apply_descrambler
for i in stream_data[key].split(‘,’)
KeyError: ‘url_encoded_fmt_stream_map’
目前使用的pytube版本為9.5.3
下載了 pytube9.5.1_fixed.zip檔,並按照說明去做,還是出現相同的錯誤訊息
後來將pytube版本 降為9.5.1
再按照 說明 去試,還是出現相同的錯誤訊息
不知道哪裡有錯,請問應該如何修正?
謝謝。
請參閱YouTube影片下載(一):合併視訊和音軌的Python程式,更新PyTube程式庫,其餘程式碼不變。
另外,多數音樂類型影片或者影片中包含有版權的背景音樂,以及YouTube原創影片,目前都無法下載。
thanks,
jeffrey
作者您好:我有購買超圖解Python程式設計入門,下載電子檔好像沒有書中提到的完整範例Ch14_8.py,方便將此檔案寄e-mail給我嗎?謝謝
拍謝,實際檔名是ch14_7.py,已包含在範例檔中,謝謝!
thanks,
jeffrey
老師你好,我想問ch11的download_img.py跟download_href.py檔案,
執行的時候並沒有跑出任何東西,
似乎是images沒有辦法取得src屬性值
用print(images)是[ ]
請問問題出在哪裡呢?
請問你有上傳www資料夾到ESP8266嗎?
thanks,
jeffrey
老師你好有些問題想請教我照著14-33~14-34的作法想做一個dat的檔案但都會出現以下錯誤訊息但我有確認我的圖片檔是有存在的
No such file or directory: ‘C:\\RFID zero\\pictzero.jpg’
首先要修改路徑,例如:
然後修改.csv的內容,例如:
thanks,
jeffrey
老師不好意思,我只有買這本書,有點聽不懂,還是在書裡哪裡有寫到><
我有試著將網址改成google首頁跟yahoo首頁,發現可以擷取到src
但是google首頁的圖片 (h.status_code == 200) 跟 ('image' in MIME) 的條件都不符合無法下載
yahoo首頁的圖片可以成功下載
不太清楚各個網頁的差異是在哪裡…
抱歉,我以為是另一本物聯網相關的Python問題。在Google首頁的圖片上按右鍵,選擇「檢查」,可以看到它的圖片是SVG格式。用base64編碼成文字的方式嵌入網頁,並且設置成div標籤的「背景圖」。
thanks,
jeffrey
老師你好,
請問 ChroPath 是不是已經無法下載了?!
謝謝。
ChroPath的官網說,他們在Chrome線上商店遇到一些問題,正在修復中。這期間可以用其他瀏覽器版本,例如,新的微軟Edge瀏覽器的ChroPath版本。
感謝告知!
thanks,
jeffrey
老師你好,
在實作 課本 P10-13 ssh命令時,一直出現下列訊息:
ssh: connect to host serveo.net port 22: Connection timed out
後來將 localhost 改成 本機IP位址,再測試還是出現一樣的訊息
麻煩老師指點是哪裡有問題
謝謝。
根據serveo.net官網的聲明,因為有不肖份子利用他們的服務做釣魚詐騙,所以這幾天先暫停提供服務。
thanks,
jeffrey
老師你好,
課本 P10-20 關於 軟體版本編號:
請問老師
~ 這個符號的定義什麼,因為Google上找不到明確的定義
謝謝。
那就是10-20頁最後一段說的「相容修正版」,官方說明請參閱PEP 440文件。
thanks,
jeffrey
老師你好,
實作 課本 P10-35 發佈與測試Heroku平台上的網站
我使用 課本 P9-33 程式 實作
一直出現 Application error 頁面,但都不是 P10-37、38提到的錯誤
之後嘗試了幾次重新建置專案,還是 出現 Application error 頁面
後續也照您書上提及 開啟 Application Logs 查找錯誤所在
但實在能力不及
我將 log訊息貼上如下,麻煩老師給一些提點
謝謝。
2020-04-09T07:51:12.678215+00:00 app[web.1]: ModuleNotFoundError: No module named ‘hello’
那個錯誤訊息代表應用程式伺服器找不到名叫”hello”的模組。
第10章的範例程式主檔叫做hello.py
所以Procfile內容是:
web: gunicorn hello:app
請把其中的hello改成你的應用程式主檔名稱,再上傳一次。
thanks,
jeffrey
老師你好,
請問 課本 P11-5 下載的 IR.png圖檔
會無法開啟嗎?
我實作後,程式部分都沒問題,但圖檔無法開啟,並顯示 “檔案似乎屬於不支援的格式”
謝謝。
我執行了相同的程式,發現下載影像檔的大小是226位元組,而非正確的9527位元組。
透過檢查HTTP回應(參閱11-4頁),發現回應代碼是406,測試範例:
HTTP 406錯誤代表網站伺服器發現前來請求資源的不是瀏覽器,所以不接受請求。
解決方法是自訂HTTP標頭的’user-agent’(用戶端資訊)欄位,指定一個作業系統和瀏覽器版本,例如,底下的字串代表Windows 98系統的IE 6瀏覽器:
‘Mozilla/4.0 (compatible; MSIE 6.0; Windows 98)’
底下字串則代表macOS系統的Safari瀏覽器:
‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/605.1.15 (KHTML, like Gecko)’
底下的設定把HTTP請求的用戶端偽裝成Windows 98的IE 6瀏覽器:
http_headers = {'user-agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows 98)'} r = req.get(url, headers=http_headers) # 設定HTTP標頭 r.status_code如此,伺服器將回應200 OK;請把下載檔案中的req.get()那一行改成上面的前兩行即可正常下載。
你可以把’user-agent’值改成你目前使用的瀏覽器資訊,請參閱9-37頁的「瀏覽器開發人員工具」單元,在Request Headers欄位底下可以找到user-agent的值。
thanks,
jeffrey
老師你好,
實作 課本 P11-25 程式 下載 files路徑 下的檔案
程式執行沒有問題,但下載下來的檔案大小,和實際檔案大小不相符合
是不是又發生 伺服器不接受檔案請求的情況?
以書本上說明,selenium是實際操作瀏覽器來開啟目標網頁,
所以應該不必 自訂HTTP標頭的’user-agent’(用戶端資訊)欄位
請問老師知道如何修正嗎?
謝謝。
感謝告知!那個程式是用selenium解析網頁,再透過requests的get()方法下載。
我剛剛試過偽裝瀏覽器版本,但是無效,因為該網站伺服器要求一定要有「啟用JavaScript」的瀏覽器方可下載檔案(之前沒有這個限制)。
所以…程式要改成指揮chrome「點擊(click)」超連結來下載檔案。
請先在程式開頭引用time程式庫,我們將透過它的sleep()來設定每次點擊之後的延遲秒數(避免在短時間之內多次點擊)。
import time
程式已經透過find_elements_by_xpath()篩選出超連結元素,請修改檢查超連結元素的迴圈:
for a in links: href = a.get_attribute("href") rar = pattern.search(href) if rar: filename = rar.group() # 取出檔名 if filename not in file_set: # 如果此檔案沒有下載過… a.click() # 點擊此超連結 time.sleep(1) # 暫停1秒鐘 file_set.add(filename) # 紀錄此檔案後面原本負責執行下載的程式,就可以設成註解或者將它刪除:
儲存並執行此Python程式,你將能在瀏覽器預設的「下載」資料夾看見下載檔。
此外,我也檢查了11-14頁的「下載超連結檔案」單元的download_href.py範例檔,同樣是因為網站伺服器修改規則導致程式失效,修正後的原始碼如下(加入自訂的HTTP標頭):
from lxml import html from tqdm import tqdm import requests as req http_headers = { 'user-agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows 98)'} url = 'http://swf.com.tw/download/' page = req.get(url, headers=http_headers) # 設定HTTP標頭 dom = html.fromstring(page.text) links = dom.xpath('//a/@href') def download(url): filename = url.split('/')[-1] r = req.get(url, stream=True, headers=http_headers) # 設定HTTP標頭 with open(filename, 'wb') as f: for data in tqdm(r.iter_content(1024)): f.write(data) return filename for href in links: if not href.startswith('http'): href = url+href h = req.head(href, headers=http_headers) # 設定HTTP標頭 MIME = h.headers.get('content-type') if (h.status_code == 200) and \ ((MIME is None) or ('html' not in MIME)): print('下載檔案網址:' + href) filename = download(href) print(filename + ' 下載完畢!')我明天一早會請本書的編輯更新書本的範例原始檔,晚上應該會處理好,再次感謝!
thanks,
jeffrey
老師你好,
不好意思,上一則發問的文字部分只有:
虛線以下的文字
因為 用 複製 貼上,所以手誤
不好意思
謝謝
———————————————————————————–
老師你好,
課本 P11-41 程式:
try:
while True:
time.sleep(1)
請問 time.sleep(1) 敘述可以寫成 pass 嗎?
兩種寫法會有差別(好壞)嗎?
time.sleep(1) 會比較省電嗎?
因為前陣子剛研讀完 「超圖解 Python 物聯網實作入門」,聯想到移動式裝置的耗電問題
謝謝
Python的time.sleep()相當於「延遲、不做事」,MicroPython的machine程式庫的sleep()才是真正的睡眠(如Python物聯網動手做18-6單元所示)。
pass是「略過、不做事」,讓CPU繼續處理下個指令,沒有停歇。因此以「耗電量」來說,time.sleep()比較省電,因為CPU有停歇。
thanks,
jeffrey
老師你好:
第12章留言板的程式運行後,如果使用Safari 瀏覽器在管理頁面刪除留言會出現 Method Not Allowed
The method is not allowed for the requested URL. 。但是在 Chrome是正常的,請問這是什麼問題呢?
謝謝指教
請修改templates(樣板)裡的list.html檔,
把「重新載入頁面」的JavaScript敘述(第62行):
$.post("/delete", { id: _id }, function (data) { location.reload(); });加入true參數:
$.post("/delete", { id: _id }, function (data) { location.reload(true); // 加上true });reload()參數預設是false,代表讀取瀏覽器的快取(cache)資料;
設定成true代表強制連到網站伺服器取得最新的網頁資料。
剛剛在iPad的Safari瀏覽器測試沒問題。
thanks,
jeffrey
老師您好:
做5-2頁的時候安裝pytube 9.6.0時無法安裝
出現這樣
ERROR: Could not install packages due to an EnvironmentError: [WinError 5] 存取被拒。: ‘c:\\program files\\python38\\Lib\\site-packages\\pytube’
Consider using the `–user` option or check the permissions.
WARNING: You are using pip version 19.2.3, however version 20.1.1 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
照著打python -m pip install –upgrade pip也是不行
請問老師問題出在哪裡
那個錯誤是因為使用者權限不足而導致,請在pip命令後面加上”–user”。
另外,pytube請改用pytube3,所以安裝命令是:
也請參閱這些補充文件:
YouTube影片下載(一):合併視訊和音軌的Python程式
YouTube影片下載(五):PyTube3程式庫更新說明
thanks,
jeffrey
老師抱歉我是樓上那篇繼續問
照著您提供的’pip install pytube3 –user’跑出以下
請問該如何是好
Usage:
pip install [options] [package-index-options] …
pip install [options] -r [package-index-options] …
pip install [options] [-e] …
pip install [options] [-e] …
pip install [options] …
no such option: -u
“user”前面是兩個連續減號,拍謝,剛剛發現這個留言系統把我輸入的兩個連續減號變成單一連字號,已修正。
thanks,
jeffrey
你好,想請教書中p.12-16的問題.
當我輸入 from guestbook import db後,出現
File “”, line 1, in
File “C:\db\src\guestbook.py”, line 3, in
from flask_sqlalchemy import SQLAlchemy
File “C:\db\env\lib\site-packages\flask_sqlalchemy\__init__.py”, line 22, in
import sqlalchemy
File “C:\db\env\lib\site-packages\sqlalchemy\__init__.py”, line 8, in
from . import util as _util # noqa
File “C:\db\env\lib\site-packages\sqlalchemy\util\__init__.py”, line 14, in
from ._collections import coerce_generator_arg # noqa
File “C:\db\env\lib\site-packages\sqlalchemy\util\_collections.py”, line 16, in
from .compat import binary_types
File “C:\db\env\lib\site-packages\sqlalchemy\util\compat.py”, line 331, in
time_func = time.clock
AttributeError: module ‘time’ has no attribute ‘clock’
請問是哪在哪出現問題?
在之前,requirements.txt 的python-dateutil=2.8.0 的 = 改為 ==,是否有影響?
謝謝
感謝告知!我剛剛在Windows 10平台的Python 3.8.1執行該程式碼也發生同樣的問題。經追查後發現是Windows平台的Python 3.8.x版有bug。
我先下載目前最新的Python 3.8.3版安裝程式,執行安裝時它會偵測到系統已經有舊版的Python,所以可以直接升級。
新版Python安裝完畢後,刪除db虛擬應用程式的env資料夾,再重新建立一次虛擬環境。
SQLAlchemy和相關Python程式庫模組也要更新,這是更新後的requirements.txt檔內容:
在虛擬環境中安裝好這些程式庫之後,啟動虛擬環境裡的Python,測試執行讀取資料庫檔沒有問題:
thanks,
jeffrey
老師 我直接拿python案例檔案的yahoo.py直接執行(ch06裡)
一開始出現以下一長串字母
不太了解為什麼會這樣
另外
商品數量有正確顯示35個
而它卻僅顯示5筆資料
這樣是正確的嗎?
DevTools listening on ws://127.0.0.1:2417/devtools/browser/e75b0a3b-620f-437f-b8b1-5dad7f6a5f8b
[0624/214752.364:INFO:CONSOLE(1)] “[object Object]”, source: https://s.yimg.com/zq/searchv3/auctionSearch.51115c19e523573600e5.js (1)
[0624/214752.493:INFO:CONSOLE(0)] “Access to XMLHttpRequest at ‘https://udc.yahoo.com/v2/public/yql?yhlVer=2&yhlClient=rapid&yhlS=2092111218&yhlCT=2&yhlBTMS=1593006472370&yhlClientVer=3.53.19&yhlRnd=D78hv3JwIRtZTZsN&yhlCompressed=0’ from origin ‘https://tw.bid.yahoo.com’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.”, source: https://tw.bid.yahoo.com/search/auction/product?kw=%E7%A5%9E%E8%87%82%E9%AC%A5%E5%A3%AB&p=%E7%A5%9E%E8%87%82%E9%AC%A5%E5%A3%AB&sort=-ptime (0)
我剛剛測試執行沒問題,請把第10行設成註解,不隱藏瀏覽器看看它的運作畫面:
# option.add_argument('headless') # 新增隱藏(無頭)參數資料只顯示5筆,是因為我在第28行定義了一個size變數,若total值大於或等於5,size就是5,否則設定成total值:
第38行迴圈裡的判斷條件,會讓迴圈執行5次之後中斷:
if index == size: breakthanks,
jeffrey
你好,
想問有關p.13-21和p13-24結果如何取得
當我在虛擬環境啟動bot_echo.py後,再啟動ngrok得到https網址,是否將該網址copy and paste在line的Webhook URL 中使用?
當我按Verify 後,它彈出’An error occured when verify Webhook URL’.
請問如何activate 機械人程式,再得出結果?
Thanks very much
請對照13-17「LINE聊天機器人的訊息格式」一節,按下Webhook URL欄位的”Verify(核實)”鈕,LINE平台將送出一個文字訊息”Hello, world”,以及一張貼圖給Webhook設定的callback函式網址。
我們自訂程式的callback路由(13-13頁),只要收到LINE的任何訊息,都會傳回”ok”,而LINE伺服器收到了ok,就知道callback函式有正確回應,所以顯示”Success(成功)”。
後來的Python程式修改了callback,只會回應特定的訊息,例如;”悄悄話”,不理會”Hello, world”,所以”Verify(核實)”功能誤認我們的callback程式有問題,但這並不影響我們的LINE程式運作。
你可以把callback路由改回13-13頁的程式碼再測試看看。
thanks,
jeffrey
你好,
當我嘗試測試p.13-26悄悄話程式時,再把ngrok(eg.https://093410069427.ngrok.io/callback)加入webhook url後再press ‘verify’,
彈出’An error occurred when sending the webhook’,而終端機有時顯示’linebot.exceptions.LineBotApiError: LineBotApiError: status_code=404, error_response={“details”: [], “message”: “Not found”}’
請問有甚麼問題?
Thanks very much
剛剛執行第13章的bot.py檔,也就是書本13-13頁的程式,再啟動ngrok,測試LINE的Webhook沒問題:
Webhook欄位只是讓我們填寫接收LINE訊息的回呼函式路徑,即使沒有通過驗證也沒有關係,不影響我們自訂的LINE程式運作,原因請參閱上一則留言。
thanks,
jeffrey
您好:
近期想學python這個程式語言,那覺得您的書我蠻喜歡的於是就買了,
那我想問這本書的使用方法,有需要按照書籍的章節順序來進行學習嗎?
還是我能夠跳著看我需要的部份呢?
前五章包含Python基礎程式實作練習,建議至少先依序練習完這5章再跳讀。
thanks,
jeffrey
請問13-14頁的ssh -R 80:localhost:80 serveo.net指令為何會出現ssh: connect to host serveo.net port 22: Connection refused的錯誤?
應該是serveo.net服務掛了,請先改用其他服務。
thanks,
jeffrey
目前改成ssh -R 80:localhost:80 ngrok後出現ssh: Could not resolve hostname ngrok: \265L\252k\303\321\247O\263o\245x\245D\276\367\241C要如何解決?
或是其他服務能使用哪些呢?
ngrok的操作說明,請參閱10-16頁。
thanks,
jeffrey
依照10-16頁的步驟再次嘗試13-14頁的ssh -R 80:localhost:80 ngrok.io後出現ssh: connect to host ngrok.io port 22: Connection refused,仍找不出原因,請老師幫忙。
serveo.net和ngrok.io就好比是兩家電信公司,都提供相同的聯網服務,既然採用ngrok.io,就不用再使用serveo.net。
所以,按照10-16頁的說明啟用ngrok.io,外界就能連入你的電腦了。
thanks,
jeffrey